What? 알고리즘의 예상되는 실행 시간을 표현한 것
타이머로 실제 시간을 측정하는게 아니라, 알고리즘이 실행될 때 동작하는 모든 연산의 횟수가 몇 번인지를
n(입력데이터 크기)에 관한 식으로 나타낸다. O(n)
why?
실제 시간은 실행환경(하드웨어,운영체제,컴파일러 등)에 영향을 받기 때문에
"이 알고리즘을 수행하면 231ms가 걸립니다"보다는
"이 알고리즘을 수행하면 30회의 연산이 일어납니다"라고 표현한 뒤,
자신의 환경에서 1회당 몇 ms가 걸리는지 확인하는 것이 정확하기 때문!!
함수식으로 표현하기 때문에 입력데이터의 크기가 달라져도 그에 맞는 결과를 도출할 수 있기 때문!!
How?
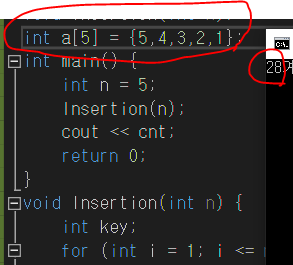
ex) 삽입정렬 알고리즘 : 정렬된 부분집합 A와 정렬되지 않은 부분집합 B로 나누어, B의 한 요소를 꺼내 A에 들어갈 위치를 찾아서 끼워넣는 방법. 반복하여 B가 공집합이 되면 정렬이 완성된다.
시간복잡도를 구할 때는 비교연산(<,>,<=,>=), 교환연산(=)을 중심으로 구하면 된다.
void Insertion(int n) {
int key;
for (int i = 1; i <= n - 1; i++) { //(1)외부루프는 n-1회
key = a[i]; //(2)외부루프에 의해 교환연산이 n-1회 일어남
int j;
for (j = i - 1; j >= 0; j--) { //(3)내부루프는 최대 i회
if (a[j] >key){ //(4)외부르프x내부루프에 의해 비교연산 최대 (n-1)+(n-2)...1=n(n-1)/2회 일어남.<-등차수열의 합
a[j + 1] = a[j]; //(4-1)조건에 의해 교환연산이 최대 n(n-1)/2회
}
else{
break;
}
}
a[j + 1] = key; //(5)외부루프에 의해 교환연산이 n-1회 일어남
}
}
- 최악의 경우(역순으로 정렬되있음) =
1*(n-1) + 2*(n(n-1)/2) + 1*(n-1) = n^2+n-2 = O(n^2)
(2) (4,4-1) (5)
- 최선의 경우(이미 정렬되있음) =
1*(n-1) + (n-1) + 1*(n-1) = 3n-3 = O(n)
(2) (4) (5)
!!보통 못해도 이 정도의 성능을 보장한다는 의미로, 최악의 시간복잡도를 많이 사용한다!!
!!시간복잡도는 n의 최고 차수만 나타낸다!!
why?
최고차수가 아닌 항의 계수가 아무리 높아져도 최고차수항에 비해 영향이 미미하기 때문이다.
따라서, 위와 같이 실제 실행되는 연산의 횟수를 확인하고 계산해도 되지만
n의 차수를 높이는 반복문을 중심으로 가장 자주 실행되는 연산만 간단하게 계산해도 충분하다.
O(4) = > O(1)
O(n^2+2n) => O(n^2)
Try! 실제로 횟수를 확인해보았다.(각 비교,교환 실행문마다 카운트 함..(n=5))

+추가 예제
#include<iostream>
using namespace std;
int main() {
int n = 5;
int cnt = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
cnt++;
}
}
cout << cnt << endl; //output: 25
//앞서 말했듯이, 반복문을 중심으로 계산하면 되므로 시간복잡도는 n*n= n^2이 된다.
cnt = 0;
int i = 0,j=0;
for (; i < n; i++) {
for (; j < n; j++) {
cnt++;
}
}
cout << cnt << endl; //output: 5
//하지만, 반복문이 중첩되어 있더라도 언제나 두 반복문 범위의 곱은 아니라는 것에 유의하자.
//위의 경우, 범위가 따로 놀기 때문에 cnt++가 포함된 루프만 생각해서 시간복잡도는 최대 n이다
return 0;
}다양한 시간복잡도
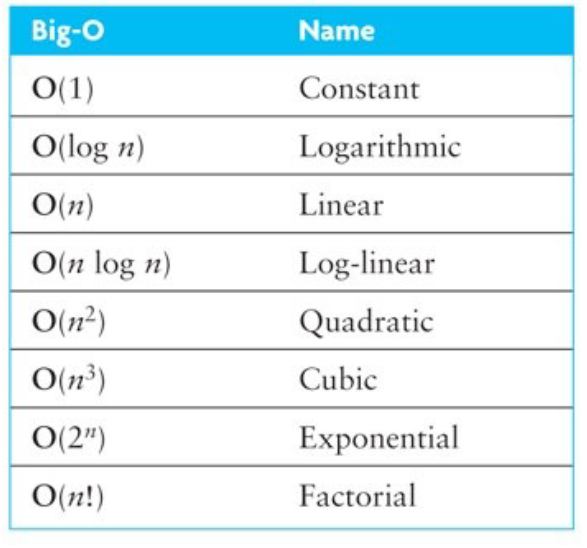
!! 전산학에서 log의 밑은 2이다 !!
+ O(1)이라는 말은 데이터를 다 보지도 않고 무언가를 판단한다는 뜻이다. 그렇기 때문에 정렬이 되있다는 등 특수한 상황이 필요함.
+해쉬의 시간복잡도는 o(1)이다. 13이면 나누기 10을 해서 1페이지 3번을 찾는거니까.
비교연산이 한번밖에 없으므로 o(1)이고 이건 환상적인 복잡도이다. 데이터가 아무리 많아져도 비교연산이 최대한번이라는 뜻이니까.
+ log 2n인지 log10n인지는 중요하지 않다. 분모/분자 꼴로 바꾸면 의미가 없으니까.
+최대복잡도가 log n이면 꽤 괜찮은 복잡도이다. 데이터의 양이 100배가 늘어나면 log10일때로 생각하면 연산시간은 두배밖에 안늘어나니까.
+ 하한이 O(n)이 존재하는지도 증명되지 않은 문제를 np-complete 라고 한다.(어려운 문제..^^..)

그래프를 보면, 지수승으로 커지면 데이터의 양이 조금만 많아져도 그 연산량이 기하급수적으로 증가하는 것을 확인할 수 있다. 여기서 우리가 알고리즘을 짤 때, 시간복잡도를 고려해야 하는 이유가 드러난다.
시간복잡도를 고려하는 이유
ex) 우리나라 인구 5000만명중에서 한 사람을 조회하는 알고리즘 2개가 있다.
A알고리즘: O(log n)
B알고리즘: O(n^2)
->A알고리즘은 25번, B알고리즘은 2500000000000000번의 연산을 수행한다.
Try! 재미로 내 컴퓨터에서 1억번의 연산을 수행하고 시간을 측정해보았다. ㅎㅎ

즉 1억번에 0.2초 정도 걸렸다. 실행할 때마다 0.2~0.4초까지 나오더라..
참고로 실행환경은 인텔® 코어™ i5-7200U 프로세서(최고 3.10 GHz) 기준이다.
1Ghz는 1초에 10^9(10억)개의 단계를 처리할 수 있다고 한다.
그럼에도 저 정도의 시간이 나온건..다른 변수가 확실히 많다는 뜻..?
->A알고리즘은 1초도 안되는 시간이 걸린다.
->B알고리즘은 120일 정도 걸린다..
하드웨어를 발전 속도가 매우 빠르기 때문에(무어의 법칙: 1년만에 반도체 집적률이 2배씩..)
소프트웨어의 발전 속도가 상대적으로 느리게 느껴지긴 하지만...
그럼에도 우리는 시간이란 소중한 자원을 낭비하지 않기 위해서 언제나 시간복잡도를 낮추기 위한 노력을 한다.
이러한 노력을 최적화라고 부른다.
Tip
추가로 알고리즘 문제를 풀 때 시간복잡도를 대략적으로 맞추는 방법을 소개하려 한다.
(백준,swea를 이제 막 풀기 시작한 분들을 위해서 쓴 글입니다! 참고해주세요ㅎㅎ)
여기서 시간제한 1초가 의미하는 것은, 내 코드를 실행했을 때 실행시간이 1초 내여야한다는 것을 뜻한다.
대부분의 환경에서 1억번 연산이 1초 정도 걸리기 때문에,
내 코드에 제일 큰 테스트케이스를 돌려도 연산이 1억번 내여야만 통과가 된다는 것이다.
그러므로, 문제를 풀기 전에 시간 제한과 입력 데이터의 수를 확인하고 나서
어느정도의 시간복잡도로 코드를 짜야겠다고 계획을 하고 코딩을 하는 것이 좋다.
1. 시간 제한, 최대 입력 데이터의 크기를 확인하고 내가 짜야하는 코드의 시간복잡도를 생각한다.
| 데이터 수 | 시간복잡도 |
| 10^8 | n,logn |
| 10^6 | nlogn |
| 10^4 | n^2 |
| 500 | n^3 |
| 20 | n!,2^n |
-> 데이터의 크기가 10^8개일 떄, 시간복잡도가 n, log n 이어야지 1억번의 연산 내로 실행된다.
-> 데이터의 크기가 10^6개일 때, 시간복잡도가 nlog n이어야지 1억번의 연산 내로 실행된다.
.....
2.그에 맞춰서 코딩을 한다
3.가장 큰 테스트 케이스를 넣어본다.

4.출력 시간을 체감해본다 or 프로파일링 기능을 사용해서 측정해본다 or <time.h>를 추가해서 시간을 출력해본다
프로그램을 실행했을 때, 바로 출력값을 확인할 수 있다면 대부분 1초 내에 실행되는 코드이다.
하지만 조금 몇 초 기다려야지 값이 나온다면?? 코드 제출을 하면 '시간초과'를 볼 확률이 높다ㅎ
물론 콘솔에 뜨는 시간으로 추측하기엔 꽤나 부정확하지만.. 알고리즘을 잘못 짰을 때 가장 먼저 드러나는 부분
아닌가 싶다. 만약 이런 경우, 자신의 코드를 한번 되돌아보자!!!
+난 정말 제대로 짰는데 시간초과가 뜨거나 좀 느린 것 같다?싶으면 다음 경우를 확인해보자.
1)디버깅 / 릴리즈 모드:
디버깅모드는 추적할 수 있는 정보가 실행파일 안에 들어가는 모드이다. 반면에 릴리즈모드는 프로그램을
배포하기 위해 컴파일하는 모드이다. 자질구레한 정보는 제외하기 때문에 컴파일 속도가 빠르다.

2) cin, cout으로 입출력을 반복:
cin, cout 보단 scanf,printf가 훨씬 빠르다.
나는 집합의 표현 문제에서 이걸 경험했다..cin을 쓰면 시간초과가 뜬다.
3)그 외의 모든 반복문들..
초기화가 필요하면 memset을 사용하는 경우가 많지만, 만약 직접 이중포문으로 초기화를 한다면 이 부분이 시간을 많이 잡아먹을 수도 있다. 주요 알고리즘이 아니라고 대충 넘어간다면 안된다! 또한, 범위의 끝까지 갈 필요가 없는 반복문인데 끝까지 가게 만든 경우도 시간초과가 발생한다. 이런 경우 적절히 break를 걸어줘야 한다.
처음 시간복잡도에 대해 생각해보기에는 로마 숫자 만들기가 좋은 것 같다.
아직 많이 부족하기 때문에 틀린 부분이 있을수도 있어요..
댓글로 알려주시면 정말 감사할 것 같습니다ㅎㅎ
학교에서 이산수학 책으로만 시간복잡도 몇 번 계산해보고,
코딩하면서 써먹으려니 뜬구름 잡는 것 같은 기분을 느낀 적이 있습니다.
조금 야매스럽기도 하지만! 저같은 초보자 분들에게 조금이나마 도움이 되었으면ㅎㅎㅎ
'Basic > Algorithm&Data Structure' 카테고리의 다른 글
| PL 주요문제풀이(c,java) (0) | 2023.04.18 |
|---|