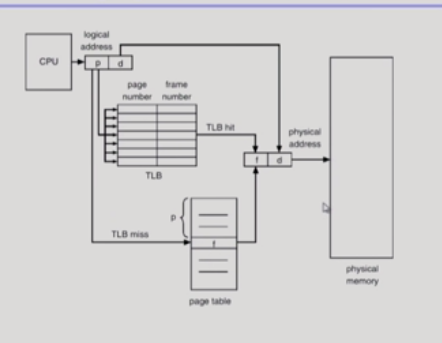
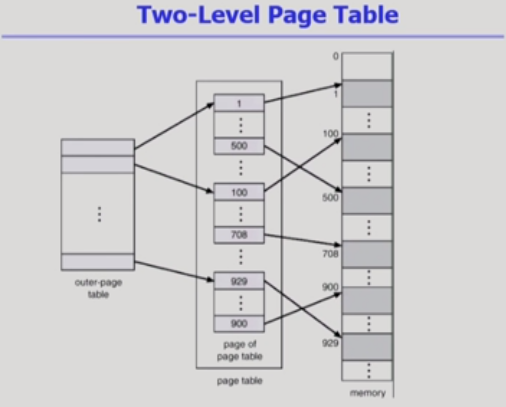
*참고: http://web.mit.edu/rhel-doc/4/RH-DOCS/rhel-isa-ko-4/s1-memory-concepts.html#S2-MEMORY-VIRT-SIMPLE*
*디맨드 페이징을 쓴다는 가정하에 포스팅*
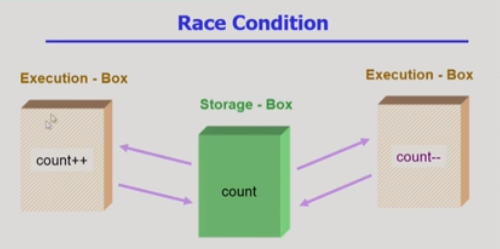
What?
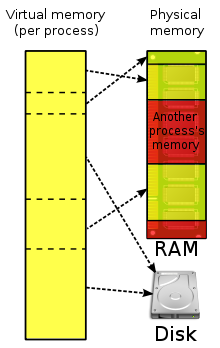
,실제 주기억장치보다 큰 메모리 영역을 제공하기 위해 운영체제가 제공하는 논리메모리이다.
보조기억장치에 존재하며, 프로세스의 주소공간 중에서 필요한 부분만 가지고 있다. (이전편 참고)
또한, 캐시의 기능을 하며(논리메모리만 검색하면 됨) 공유메모리를 가능하게 한다.(어떻게?)
이 어플리케이션의 기계 코드 용량은 10000 바이트라고 가정해봅시다. 또한 데이터 저장 및 입/출력 버퍼에 5000 바이트가 필요하다고 가정합니다. 이러한 경우 이 어플리케이션을 실행하기 위해서는 최소한 15000 바이트의 RAM이 필요합니다. 만일 1 바이트라도 부족하다면 이 어플리케이션을 실행할 수가 없습니다.
하지만 메모리 접근은 순차적이고 지역화되어 있다는 내용을 다시 생각해보십시오. 이러한 특성으로 때문에 이 어플리케이션을 실행하는데 필요한 메모리 용량은 15000 바이트 보다 훨씬 적습니다. 단독 기계 명령어를 실행하기 위해 필요한 메모리 접근 방식을 예를 들어 보겠습니다:
-
메모리에서 명령을 읽어옵니다.
-
명령어가 필요로하는 데이터를 메모리에서 읽어옵니다.
-
명령이 완료된 후 결과가 메모리에 다시 기록됩니다.
매번 메모리에 접근하는데 필요한 실제 바이트 수는 CPU 아키텍쳐 및 실제 명령어와 데이터 유형에 따라 달라집니다. 그러나 한 명령어를 실행하는데 각 메모리 접근 유형마다 100 바이트의 메모리가 필요하다고 가정해본다면 이 경우에는 300 바이트가 필요합니다. 즉 어플리케이션의 전체 15000 바이트 주소 공간을 사용하는 것보다 훨씬 적은 메모리 용량을 사용합니다. 따라서 만일 어플리케이션 실행시 필요한 메모리 요건을 기억할 수 있는 방법을 찾을 수가 있다면, 어플리케이션의 주소 공간 보다 적은 메모리를 사용하여 어플리케이션을 실행하는 것이 가능합니다.
어플리케이션의 나머지는 디스크에 남습니다.
Issue?

ex.
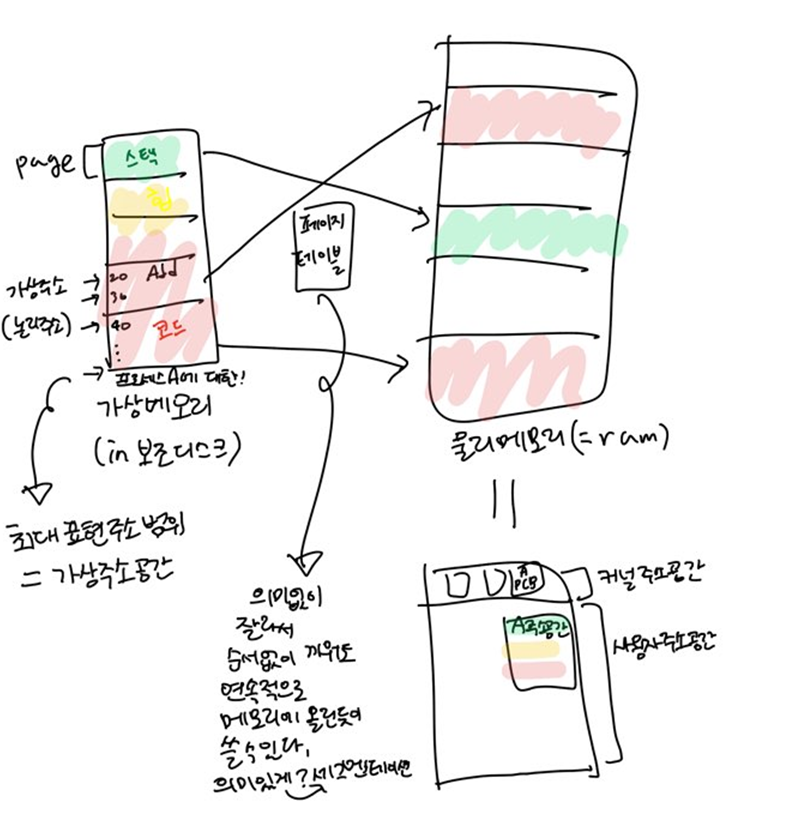
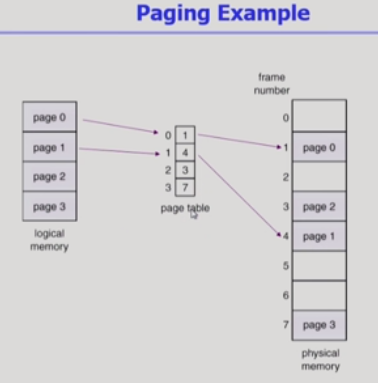
필요한 페이지만 실제메모리에 올려두고
아닌 페이지는 디스크(스왑아웃)로 보내두고
페이지 테이블엔 invalid 표시해둔다.(디맨드 페이징이라서 그럼)
접근할 때, invalid라면 페이지 폴트 난 것이므로
IO작업(커널도움)으로 디스크에서 가져와야한다.
(이것이 바로 소프트웨어 인터럽트!)
IO작업은 굉장히 느리므로
페이지폴트가 나는 횟수가 성능 좌우.
즉,page 교체시 뭘 교체할건지 잘 골라야함.
(Optimal algorithm)
Solving?
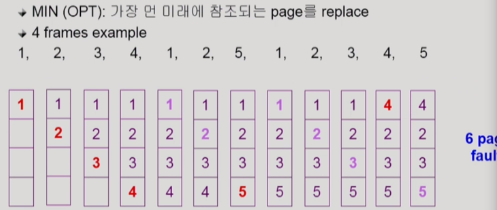
OPT: 가장 먼 미래에 어떤 페이지 참조하는지 알고 있다는 가정하에, 그 페이지를 교체
but 이건 알고 있어야되기 때문에 실제에선 미래보단 과거를 본다
FIFO: 가장 일찍 들어온 것을 가장 먼저 내보낸다.
but 프레임 커질수록 폴트 더 발생(왜?..혹시 갯수가 늘어나면 그만큼 확률도 떨어져서 그런가)
LRU(Least Recently Used):제일 오래전에 사용한거를 내쫒는다
->FIFO랑 다른 점은 먼저 들어왔어도 재사용 됐으면 안쫓아낸다는 사실이다//이 방법 젤 많이 쓴다
->링크드리스트로 처음 들어오면 밑에 달고, 뺼 때는 젤 위에꺼 뺸다.비교 필요 없다. O(1)
but 이번에 한번만 들어오고 앞으로 안들어올 애를 두고, 꾸준히 많이 들어오는 애를 보낼수도.
LFU(Least Frequntly Used): 가장 참조횟수가 적은 페이지 순으로 내쫓는다.
->O(n)...heap으로 구현해서 O(logn)에 가능.
but 이제 많아지려는애를 쫓아낼수도

밑에 정리 필요
캐슁환경;한정된 빠른공간에 요청된 데이터 저장해 뒀다가 후속요청시 캐쉬로부터 직접 서비스하는 방식
페이징의 TLB,캐쉬,버퍼,웹(얘는 단일시스템 아니고 다른 시스템에서 가져옴. 내 컴터에서 저장된걸로 보여줌)
swap)페이징의 캐쉽 적용 환경
file)캐쉬(cpu와 메인메모리 사이)의 적용환경
사실 lru,lfu는 버퍼랑 웹캐싱에만 쓰이지 페이징에는 안됨.
폴트 발생해서 새로 올라가면 접근시간 알 수 있어도 이미 있는 경우라면 참조만 해가기 때문에 정보 모름.
lru비슷하게 구현한 알고리즘이 클락 알고리즘임.
할당은 어떻게 잘 해두나? [사진]
ㄴ사실 lru.lfu같은 알고리즘 쓰면 알아서 조절되긴한다. (글로벌 리플레이스 활용)
<->로컬리플레이스(자신에게 할당된 프레임 내에서만 리플레이스..자기몫 나눠주고 알아서 바꿔써라)
+뭐가 더 좋을까?
폴트 너무 자주나면~~>Thrashing:
막는 알고?
워킹셋 알고리즘)

'Basic > OS' 카테고리의 다른 글
| 메모리 관리, 페이징, 세그멘테이션 (0) | 2019.10.26 |
|---|---|
| 데드락(Deadlock, 교착상태) (0) | 2019.10.18 |
| 프로세스 동기화 (0) | 2019.10.11 |
| 프로그램 생성과 종료,cpu 스케줄링 (0) | 2019.10.04 |
| 프로세스와 스케줄러, 스레드 (0) | 2019.09.30 |