오픈소스란? 소스코드를 공개하여 누구나 수정,배포할 수 있게 만든 소프트웨어
1980년대부터 하드웨어 뿐만이 아니라 소프트웨어에도 저작권이 필요하다는 인식이 생겼다. (빌게이츠 힘씀)
그래서 라이센스가 생겨서 모두 돈주고 쓰게 됐지만 여기에 반감을 가진 사람들이 프리웨어 선언을 함!
*프리웨어-공짜가 아니라 수정,재배포가 자유롭게 가능하다는 것
ㄴ리눅스->레드햇,우분투,데비안
ㄴ그 외->안드,크롬,mysql.. : 아, 오픈소스의 정의를 정확히 알게 되니 왜 mysql이 오픈소스라서 써야하는지 알겠군! 안드는 근데 오픈소스라도 수정은 구글만 가능함.
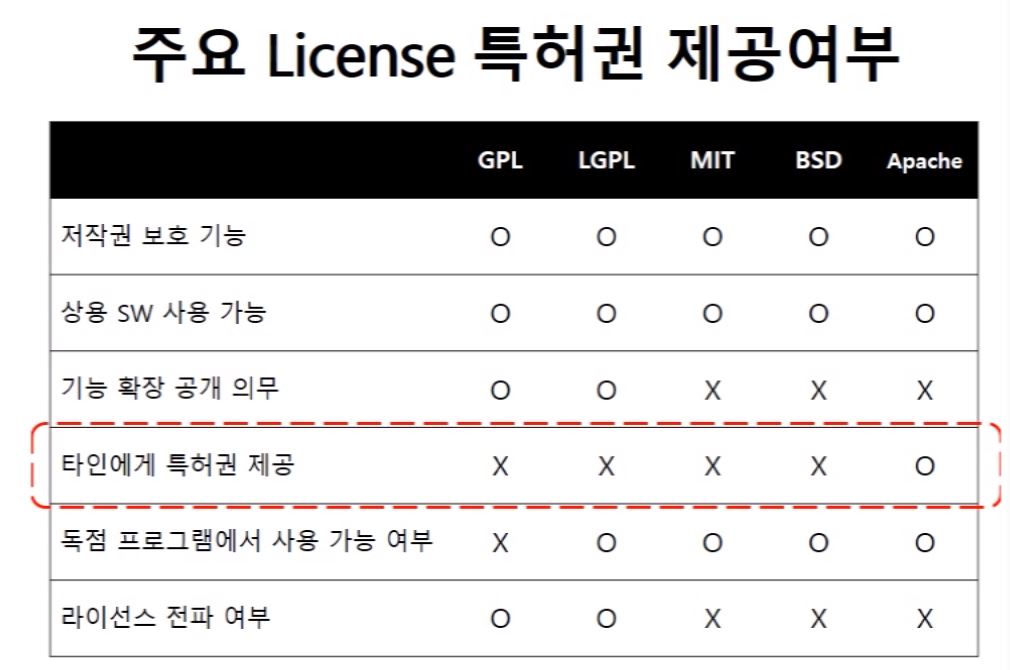
+권한을 사용자에게 더 줄 거냐, 원 저작자에게 더 줄거냐의 문제?
원저작자에게...:
GPL (마음대로 쓸 수는 있지만 수정한 것은 수정한 것도 오픈해야함. 기업이 불리),
LGPL (LGPL은 less gpl로, 컴파일 된 파일을 호출만 하는거면 공개안해도 된다는거)
사용자에게...
MIT,BSD,Apache (수정한 뒤 오픈하지 않아도 됨. 되도록 이 쪽 라이센스를 쓰자!)
+모바일 측면(갑자기 왜 나오는지는 모르겠지만..)
v1~v3.0/v3.1~v5.0/v5.1~
같은 안드로이드라도 이렇게 세가지 다른 os다. 메모리 관리법이 다르기 때문.
초기버전은 지원하려면 3배는 많은 비용이 드는데 아직 동남아는 초기버전 쓰는 곳 많아서
지원범위 정할 때 신중히..! (앱 성공하려면 중국진출을 해야한다..)
중국은 aosp라고 안드중에서도 딴거 다 뺴고 os만 들어있는 os 기반으로 쓴다. 즉
한국의 안드개발자와 중국의 안드개발자 스타일 많이 다르다는 것.
~~~모바일에선 사용자가 많아도 수익이 적다.
장비나 오라클 사지도 못하고, 많은 사용자를 어떻게 견디냐?
그 대안으로 백엔드도 오픈소스화 되는거임(아 모바일 때문에 오픈소스가 중요해진거구나..)
~~~
+백엔드 측면
Node.js를 예로 들자. 이 기술의 장점은~
->싱글스레드 사용.(여기서 os 공부한게 도움이 되는구나!ㅠㅠ)
원래 user level에서 락킹(멀티스레드에서만 고려)걸고 이런 저런 처리를 하는데 node.js는 커널레벨에서 처리. golang도 즉, cpu가 4개면 스레드 하나만 뜨는게 아니라 cpu갯수만큼 스레드 띄우고
모든걸 비공개로 해서 콜백만 받아서 처리함으로서 개발자의 실수를 줄인다.
->npm(노드를 사용한 라이브러리 집합)이 엄청 커짐. 개발 생산성이 높아짐
->논블로킹 I/O
유저레벨의 io작업때문에 다른 유저레벨의 스레드가 기다리는게 아니라 io를 커널에 위임해뒀다가 호출하는 구조임.
->node.js의 js는 사실 껍데기고, 그 안의 소스는 사실 c++로 되어있어서 빠르다
이렇기 때문에, 어디에 적합하냐면~~
->restful api에 적합.
->db에 접속해서 data 가져오는 등 많은 I/O를 처리하는데 적합하다.
->실시간 처리에 강함
//여기까지 이해 잘 안가면 운영체제 카테고리의 글들 다시 읽자
어디에 부적합하냐면~~
->멀티스레드 앱
->큰데이터 연산(게다가 이건 python으로 다하지)
->cpiu 부하걸리는 작업(=> golang이 보완책)
->복잡한 비즈니스 로직(스프링이 건재한 이유. 스프링 클라우드 생기면서...자바가 강하게 지키고 있다)
아 이래서, node.js거리는구나! 그리고 각각 맞는 분야가 있으니 무작정 spring 버리자는거도 아님!
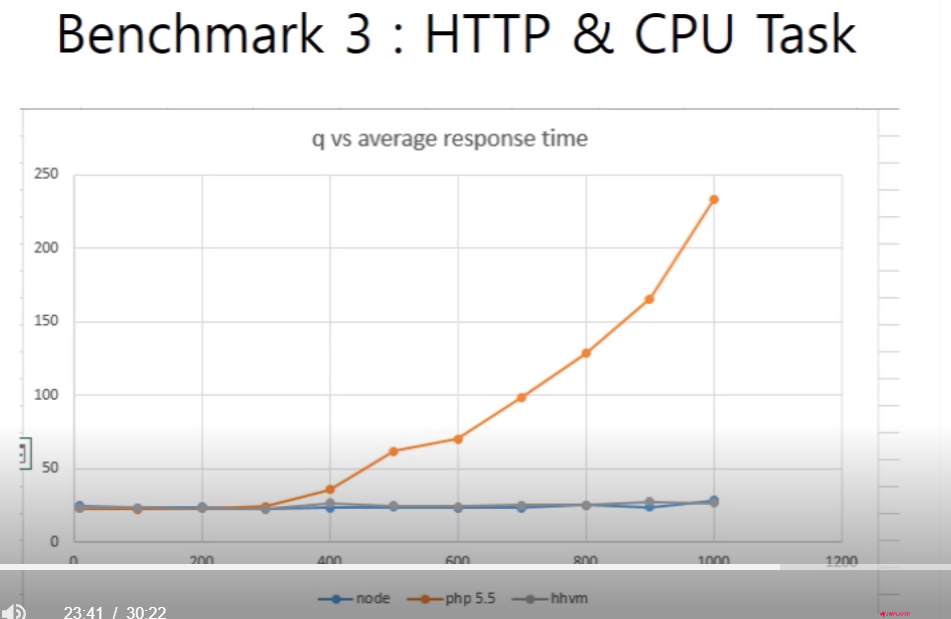
경사 오진당~~~~
여기부터 좀 가볍게 적는다!
+DB 측면
+mongoDB
NoSQL 사용하는 DBMS 종류이다.
NoSQL은 스키마가 없고, 데이터가 삽입될 때 스키마하 함께 추가되는 것이 특징이다.(자세한 것은 db 카테고리 글)

+json은 텍스트, 바이너리로 바꾼건 bson
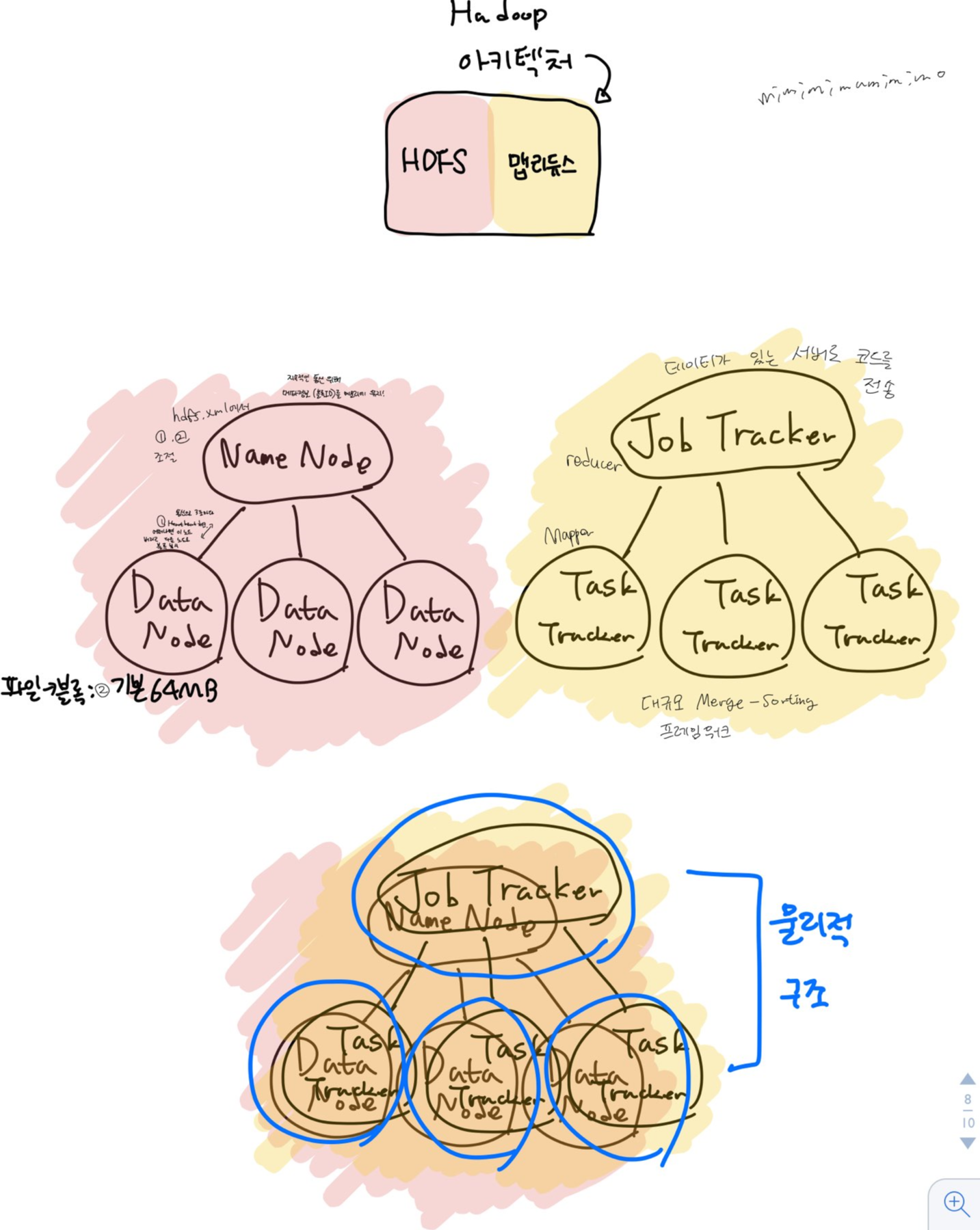
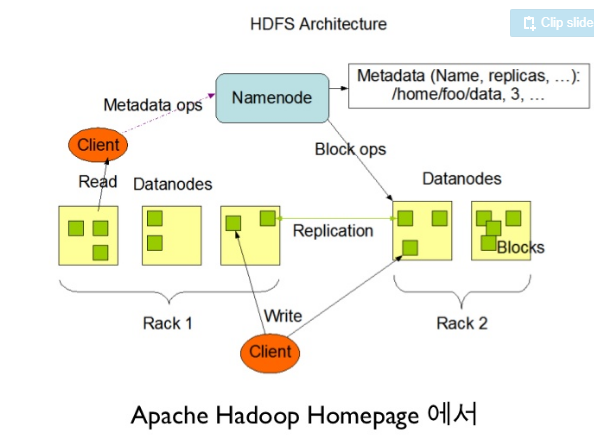
몽고db,,약간 하둡처럼 master와 여러대의 slave로 아키텍쳐가 이루어져 있다.
하둡도 비정형 데이터 대상이라서 그런가?
+오토샤딩 지원!(샤딩은 nodql 글에서 전체 갱신문제 관련)
+redis
read의 성능을 어떻게 더 끌어낼 것인가?
+이런 분산환경들을 관리하는 오픈소스가 zookeeper,etcd 등이 있음.
+클라우드 측면..
사용자 특정 시간에만 늘어나면 그 시간 전에 서버 쉽게 추가하도록 스케줄링 가능.
글로벌하게 서비스가 성장할 경우(직접 방문해서 다 하는게 아니라 aws 같은 애한테 맡김)
but 공유자원이기 때문에 IOPS 문제 보장 안될 때가 있음. 그러니 그거 보완은 사서 써야함. 많이 비쌈.
클라우드 환경에서 고려해야할 것 몇 가지
1.IOPS
2.Disk Queue Length
3.CPU Steal Time
+aws는 1년에 20시간은 장애나도 보장안하니 애저를 하나 더 돌리고 있거나 백업서버 준비해야함
클라우드 문제 발생할 가능성 많은데 여기 적진 않을 것. 필요시 찾아보자
오픈스택 캠프 참고
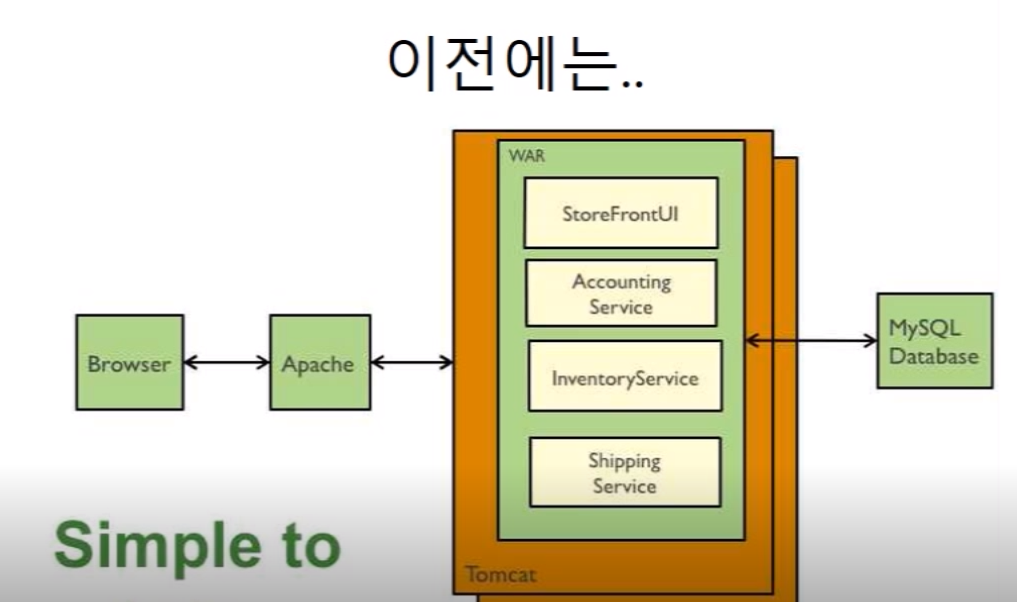
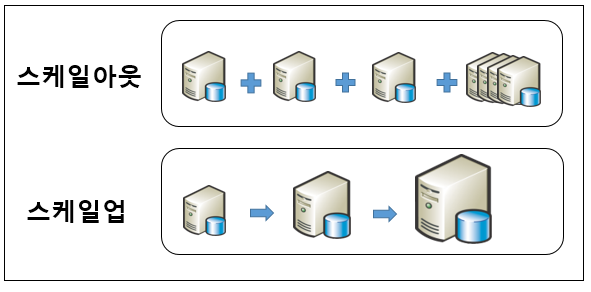
스케일업/아웃 비용->하둡 글
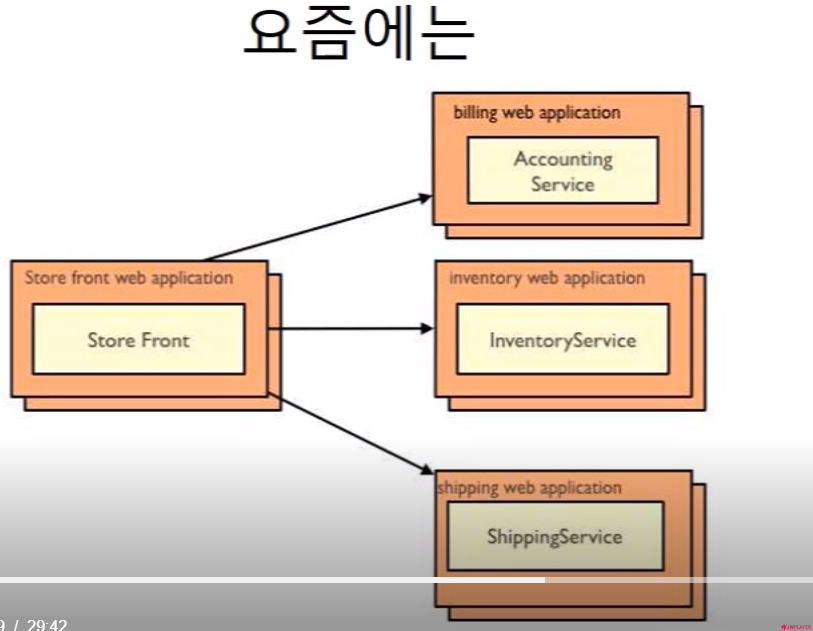
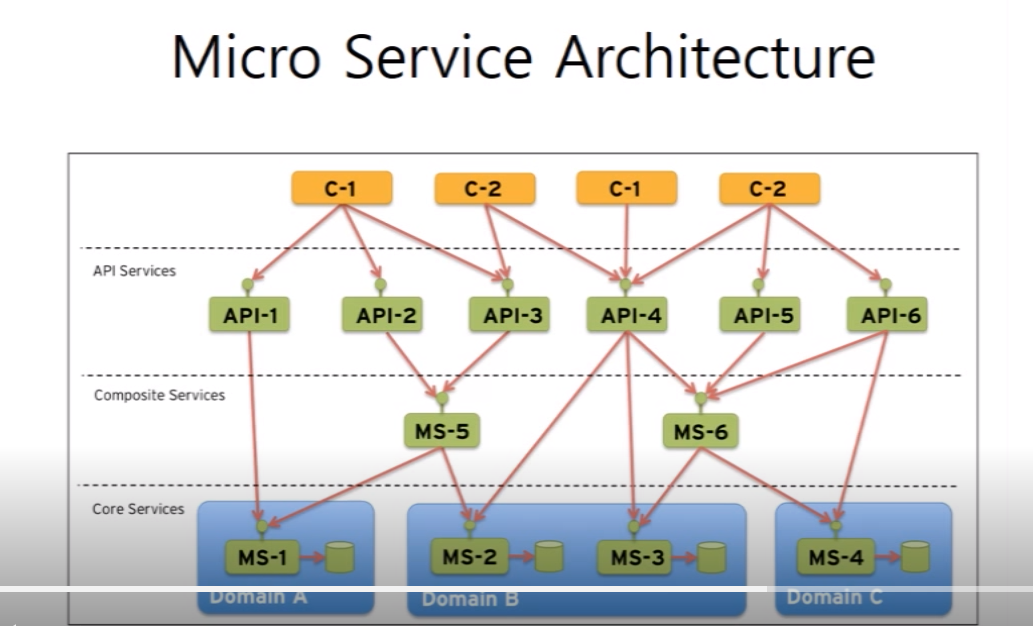
그래서 서비스가 돌아가면 이런 구조로 돌아간다! 굉장히 복잡...이렇게 큰 구조를 가장 빡세게 쓰는 곳은 현재
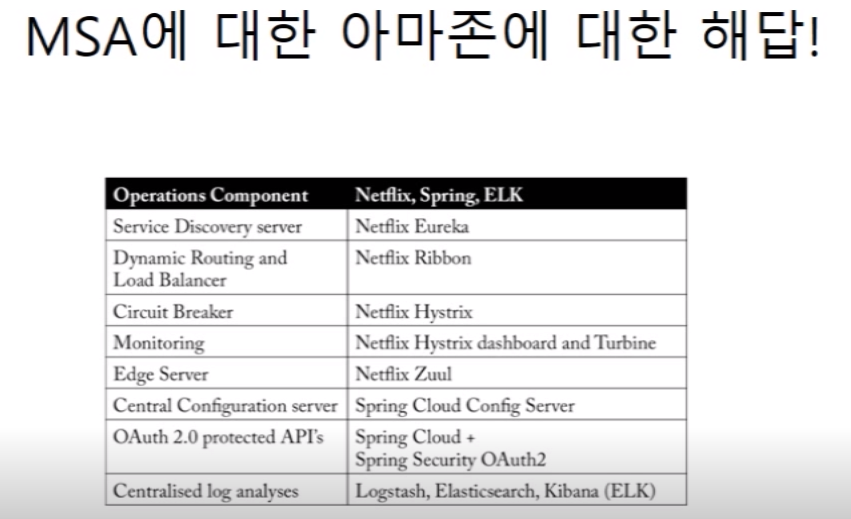
넷플릭스. aws에서 모든걸 하고있다. aws에서 로드밸런싱 처리, 특정부하 이상오면 튕기는 서킷브레이크,로그를 처리하는 ELK 스택 등의 일을
처리하는게 스프링 클라우드임. 이래서 아직 자바는 죽지 않은거고..너무 복잡한 서비스는 스프링 쓰는거구나.