국가직,지방직 9급+7급
'Basic > Algorithm&Data Structure' 카테고리의 다른 글
| <Time Complexity : 시간복잡도> 구하는 법 + 코딩 팁 (0) | 2019.07.24 |
|---|
국가직,지방직 9급+7급
| <Time Complexity : 시간복잡도> 구하는 법 + 코딩 팁 (0) | 2019.07.24 |
|---|
| 트랜잭션 (0) | 2020.01.30 |
|---|---|
| Issue: 오라클 노트북 두 개에 설치해서 db 공유 (IP의 이해) (0) | 2020.01.02 |
| Index(인덱스) (0) | 2019.12.17 |
| NoSQL (0) | 2019.12.10 |
| 정규화 (0) | 2019.12.10 |
what? http,https 둘다 인터넷 통신에서 앱계층의 프로토콜이다.
웹 브라우저를 사용해서 통신하는데, 클라이언트와 서버의 위치를 URL로 표시한다.
*HTTP: hypertext transfer protocol
*URL: uniform resource locator
여기서 말하는 resource(자원)은 웹사이트(html) 뿐만이 아니라 네트워크 상에 연결된 다양한 자원들을 포함한다.
issue! HTTP는 이름처럼 텍스트를 주고 받으며 통신하기 때문에, 전송신호를 인터셉트하면 데이터가 유출될 수 있다.
보안성을 높여 이것을 막는 것이 HTTPS이다.
how? 사용자마다 다른 암호를 제공해서 구현한다. ->공개키 암호화 방식
why? HTTPS를 지원하는 서버에 요청(Request)을 하려면 공개키가 필요하다는 것을 알 수 있다.
여기서 개발자가 고려해야할 부분, 특성에 맞게 적절하게 쓰려면~~
1. 유출되면 위험한 데이터 통신이 필요할 때 쓴다.
ex) 회원가입(위험O)/판매상품게시(위험X)
2.마케팅 적으로 유리하려면, 검색엔진이 https로 보안적용 된 것을 우선순위로 보여준다
3.CA 기업에 지불할 비용
4.비연결형의 경우 통신이 잠시 끊겼다가 재시작되면 다시 키로 인증을 받아야해서 부하가 생긴다
동작순서
CA는 민간기업이지만 아무나 운영할 수 없고 신뢰성이 검증된 기업만 CA를 운영할 수 있다.
1. 먼저 애플리케이션 서버(A)를 만드는 기업은 HTTPS를 적용하기 위해서 공개키와 개인키를 만듭니다.
2. 그 다음에 신뢰할 수 있는 CA 기업을 선택하고 그 기업에 내 공개키를 관리해달라고 계약하고 돈을 지불합니다.
3. 계약을 완료한 CA 기업은 또 CA 기업만의 공개키와 개인키가 있습니다.
CA 기업은 CA기업의 이름과 A서버의 공개키, 공개키의 암호화 방법 등의 정보를 담은 인증서를 만들고, 해당 인증서를 CA 기업의 개인키로 암호화해서 A서버에게 제공합니다.
4. A서버는 암호화된 인증서를 갖게 되었습니다. 이제 A서버는 A서버의 공개키로 암호화된 HTTPS 요청이 아닌 요청(Request)이 오면 이 암호화된 인증서를 클라이언트에게 줍니다.
5. 이제 클라이언트 입장에서, 예를 들어 A서버로 index.html 파일을 달라고 요청했습니다. 그러면 HTTPS 요청이 아니기 때문에 CA기업이 A서버의 정보를 CA 기업의 개인키로 암호화한 인증서를 받게되겠지요.
6. 여기서 중요합니다. 세계적으로 신뢰할 수 있는 CA 기업의 공개키는 브라우저가 이미 알고 있습니다!
7. 브라우저가 CA 기업 리스트를 쭉 탐색하면서 인증서에 적혀있는 CA기업 이름이 같으면 해당 CA기업의 공개키를 이미 알고 있는 브라우저는 해독할 수 있겠죠? 그러면 해독해서 A서버의 공개키를 얻었습니다.
8. 그러면 A서버와 통신할 때는 A서버의 공개키로 암호화해서 Request를 날리게 되겠죠.
issue!
CA 기업이 아니라 자체적으로 인증서를 발급할 수도 있고, 신뢰할 수 없는 CA 기업을 통해서 인증서를 발급받을 수도 있기 때문입니다.
그렇게 되면 브라우저에서는 https지만 "주의 요함", "안전하지 않은 사이트"등의 알림을 주게됩니다.
출처: https://jeong-pro.tistory.com/89 [기본기를 쌓는 정아마추어 코딩블로그]
출처: https://jeong-pro.tistory.com/89 [기본기를 쌓는 정아마추어 코딩블로그]
| TCP/IP와 UDP의 차이 (1) | 2020.02.05 |
|---|---|
| TCP 3 way handshake (0) | 2020.02.03 |
| 웹 통신 흐름 (0) | 2020.02.01 |
| Http 메소드 (Get,Post,Delete,Header..) (0) | 2020.01.31 |
| RestAPI (0) | 2020.01.19 |
what? 인터넷에서 데이터를 송수신하는 전송계층의 프로토콜이다.
where? 컴퓨터의 프로토콜 스택안에 TCP,UDP가 LAN카드(실제 케이블 신호 송수신)와 함께 있다.
*프로토콜 스택
통신을 위한 규약의 집합이다. 내부에 메모리가 있고, 여기에 각 층의 제어정보를 기록한다. 이 메모리 영역이 소켓이다.
즉, 소켓을 만든다는 것(앱층에 소켓 호출,ex 자바 소켓함수)은 이 메모리영역에 제어정보(IP,포트번호 등)를 추가하고 버퍼메모리를 준비하는 등의 작업을 하는 것이다.
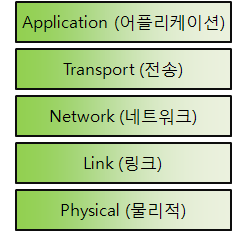
서비스 정의(HTTP,FTP,SMTP..)
데이터전송 신뢰성 보장(TCP.UDP)
패킷 전달 경로를 결정(IP)
패킷을 보내는 것 지원(과부하 안걸리게 조절 등)(이더넷)
유무선으로 데이터 송수신(IEEE)
-송신측 기기의 프로토콜 스택 동작 순서: 앱->...->물리
-수신측 기기의 프로토콜 스택 동작 순서: 물리->...->앱
=>TCP가 제어정보를 기록한 헤더를 만들고, 이를 IP담당에 보내서 송신 의뢰를 한다. 그럼
IP에선 서버측 IP 담당부분에 전달하고 그 친구는 헤더를 TCP에 보낸다.TCP는 조사하고 소켓에 정보를 기록하고,
네트워크 상태를 진행중으로 바꾼 뒤 ACK를 돌려보낸다. //이전 포스팅 참고
*UDP*

신뢰성을 보장하지 않음. 즉, 연결에 대한 사전 설정을 하지 않고, 일단 보낸다. 서버로부터의 응답이 손실되면 클라이언트는 TIMEOUT 되어 다시 보내는 방식이다.
->비연결형 프로토콜
->짧게 조회하는 DNS서버에 대한 조회, 성능 중요한 파일전송,스트리밍 서비스 등
->IP 데이터그램을 캡슐화 (user datagram protocol)
->속도 빠름
->헤더의 체크섬 등으로 최소한의 오류만 검출
->연결이 없어서 서버소켓과 클라이언트 소켓의 구분이 없다
->소켓 대신 ip를 기반으로 데이터를 전송한다
*TCP*

3-hand shake를 사용해서 연결하고, 4-hand shake로 해제하여 신뢰성을 보장함-> 메일 등 일반적인 앱 데이터 수신
->연결형 프로토콜(대부분 순차적인 데이터 송수신이 필요하기 때문에 UDP에서 발전된 것이다)
->송신자,수신자 모두 소켓을 생성해야한다(양방향 프로토콜)
->속도 느림
->손실된 경우 재전송 요청을 하기 때문에 스트리밍 서비스에 불리하다
| http와 https의 차이 (0) | 2020.02.06 |
|---|---|
| TCP 3 way handshake (0) | 2020.02.03 |
| 웹 통신 흐름 (0) | 2020.02.01 |
| Http 메소드 (Get,Post,Delete,Header..) (0) | 2020.01.31 |
| RestAPI (0) | 2020.01.19 |

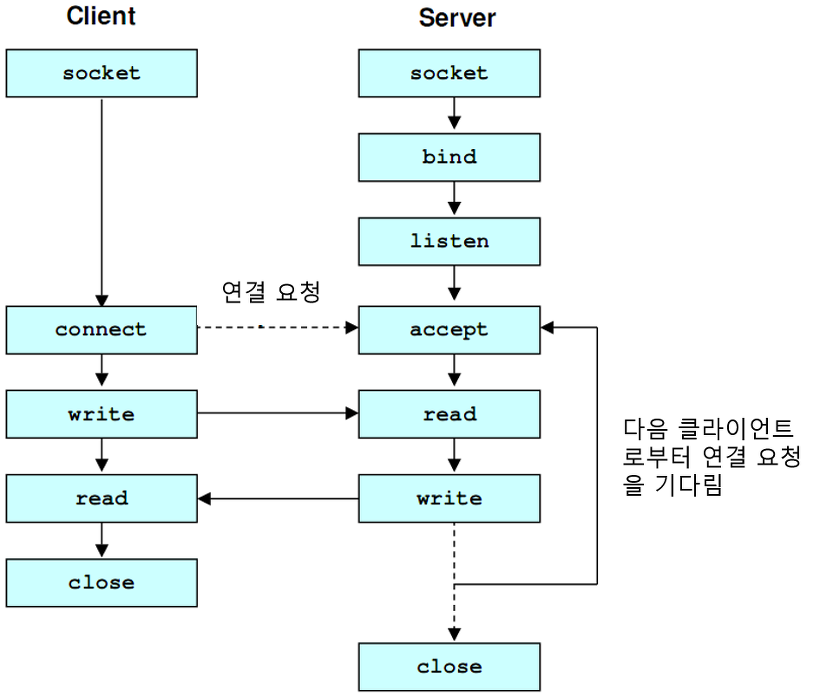
동작원리:
가도되니?응 와도 돼. 간다~~!!
*서버는 Listener가 켜져 있는 상태로 대기, 클라이언트도 서버도 ACK를 받는 순간 established(연결성립) 된다는 점에 주의하자.
SYN: 싱크로나이즈 넘버
ACK: 애크놀리지 넘버
what?
전송 제어 프로토콜(TCP)에서 통신을 하는 장치간 서로 연결이 잘 되어있는지 확인하는 과정, 방법
ex) 서버와 클라이언트 사이이에서 패킷을 전송할 때
why?
TCP프로토콜의 목적은 데이터의 신뢰도가 중요할 때 사용하기 위해 만들어졌기 때문이다.
how?
개발자가 할 수 있는 것은 이러한 특성을 파악하고 TCP와 UDP 중에서 적절한 통신 프로토콜을 선택하는 것이다.
ex)음악 스트리밍 같은 경우 조금만 불안정해도 버퍼링이 사용자에게 불쾌감을 주므로 신뢰도가 덜 보장되더라도 UDP를 선택한다.
issue! syn flooding: 존재하지 않는 클라이언트 IP로 SYN 요청만 엄청 보내서 백로그를 가득 채워, 다른 클라이언트의 요청을 받지 못하게 하는 악의적인 행위가 있을 수 있다.
| http와 https의 차이 (0) | 2020.02.06 |
|---|---|
| TCP/IP와 UDP의 차이 (1) | 2020.02.05 |
| 웹 통신 흐름 (0) | 2020.02.01 |
| Http 메소드 (Get,Post,Delete,Header..) (0) | 2020.01.31 |
| RestAPI (0) | 2020.01.19 |
거시적으로 흐름을 이해하는 것은 중요하다. 그 요소들이 형태가 무엇인지, 소프트웨어인지 하드웨어인지, 동작원리 등 물리적인 관점에서 바라보는 것도 중요하다.
| http와 https의 차이 (0) | 2020.02.06 |
|---|---|
| TCP/IP와 UDP의 차이 (1) | 2020.02.05 |
| TCP 3 way handshake (0) | 2020.02.03 |
| Http 메소드 (Get,Post,Delete,Header..) (0) | 2020.01.31 |
| RestAPI (0) | 2020.01.19 |
HTTP: 웹상에서 클라이언트와 서버 간에 요청/응답으로 데이터를 주고 받을 수 있는 프로토콜.
클라이언트->서버(요청) , 클라이언트<-서버(응답) 일 때, 요청을 수행할 때 취해야하는 방식을 http메소드로 정하는 것이다.
GET: 가져오다, 서버로부터 정보를 조회하기 위해 설계된 메소드.
how? 요청시 필요한 데이터를 쿼리스트링 형식으로 header에 담는다.
쿼리스트링이란, URL의 끝에 ? 와 함께 키,값 쌍으로 파라미터를 붙여준 문자열이다.(&로 여러개 가능)
www.mimimimamimimo.com/resource?name=value1&name=value2 <==이게 바로 header!!
issue! 이미지 같은 정적 컨텐츠는 데이터 양이 크고, 변경된 일이 적기 때문에 동일한 요청이 발생했을 경우 서버로 요청을 보내지 않고 캐시된 데이터를 사용한다. 그래서 정적컨텐츠가 캐시돼 컨텐츠를 변경해도 바뀌지 않는 경우가 종종 발생한다.
sql injection 발생가능!
when? 게시글을 조회하는 기능
POST: 게시하다, 서버의 정보를 수정하기 위해 설계된 메소드.
how? 요청시 필요한 데이터를 body에 숨겨서 보낸다.
issue! GET보단 보안성이 있지만 그래도 크롬 개발자도구 등으로 요청 내용을 확인할 수 있으므로 민감한 데이터라면 암호화가 필요하다. 그리고, 요청 데이터의 타입을 헤더에서 표시해야한다. 그렇지 않으면 타입을 유추해야 하기 때문이다.
when? body는 길이의 제한이 없기 때문에 대용량 데이터를 넣어서 보낼 때 쓴다.
게시글을 생성하는 기능
즉. GET은 동일한 연산을 여러번 수행해도 동일한 결과가 나오고
POST는 동일한 연산이라도 다른 결과를 응답할 수 있다.
DELETE: 지우다, 00블로그를 지워달라
HEADER: 서버의 헤더만 읽어와 달라.
...그 외에도 다양한 http 메소드가 존재한다.
=>get,post,delete...등 메소드들이 동사의 역할을 한다. 이런 꼴을 취하는 것이 REST 구조!
=>브라우저의 주소창은 GET방식의 요청일뿐이다. POST방식을 사용해서 보내고 싶으면, body에 숨기는 작업이 필요하기 때문에 특정 도구가 필요하다(그거그거)
=>html 첫 줄에 get,post를 지정하는 부분이 있다.
직접 API 작성해보고 post방식으로 요청도 해보는게 중요한 것 같다. json과 html과 본문이 무엇을 뜻하는지, 브라우저가 어떻게 이것을 읽는지 아는 것은 직접 해보며 알아야 한다.
외우지 말고, 무언가 시험을 위해서가 아니라 내가 실제로 쓰기 위해 알아가는 것임을 명심하자.
그러면 자연스레 단순구현이 아닌 쓰는 목적에 맞는 것을 쓸 수 있을 것이다!
| http와 https의 차이 (0) | 2020.02.06 |
|---|---|
| TCP/IP와 UDP의 차이 (1) | 2020.02.05 |
| TCP 3 way handshake (0) | 2020.02.03 |
| 웹 통신 흐름 (0) | 2020.02.01 |
| RestAPI (0) | 2020.01.19 |
What? 여러 개의 쿼리를 하나의 작업 단위로 묶은 것. (mysql에선 start transaction~commit까지임)
ACID 성질을 만족함
-Atomicity(원자성): all or nothing (아래의 why 참고)
-Consistency(일관성): 기본키 외래키 제약 조건 등이 어떤 커넥션에서든 조건이 동일해야 한다
-Isolation(독립성): 복수의 트랜잭션이 순서대로 실행되는 경우와 같은 결과를 얻을 수 있어야 한다.
ex) 방 10개 중, a와 b가 같은 화면을 보고 동시에 예약하면 2개 빼져야하는데 고립성 보장 안되면 1개만 빠짐.
직렬화 기능을 제공하여 격리수준을 더티읽기(a가 커밋 안했어도 9개로 읽음)~애매한 읽기(1회결과=?2회결과)로 조절 가능하다.
-Durability(지속성): 성공적으로 커밋되고 나면 하드웨어적or소프트웨어적 문제 발생해도 보존되어야 한다.
트랜잭션 관리를 잘 해야한다!
Why? 하나의 단위인데 그 안에서 A 수정 후 B 수정인데 B가 not null 조건에 위배된다면
이미 수행된 A를 어떻게 하느냐, 이런 것을 처리하기 때문이다.
issue!
제약 조건 위배->사용자 요청으로 철회되는 상태
교착상태, 타임아웃->DBMS가 철회
아무 문제 없음->커밋된다
+교착상태: 서로 잠금을 건 자원에 잠금이 필요한 처리. 아무리 기다려도 바뀌지 않는 상태-> 트랜잭션을 자주 커밋해서 작은 단위로 쪼개서 교착상태의 가능성을 낮춰서 해결할 수도 있다.
+데이터베이스 시스템 구조
(질의처리기 | (페이지버퍼) 저장시스템 )
DBMS는 데이터를 디스크에 저장하고, 일부는 메인 메모리에 유지한다. 저장의 단위는 페이지.
여기서 페이지버퍼를 관리하는 버퍼관리자의 역할이 중요하다!
버퍼교체알고리즘에 의해 커밋이 완료되지 않았지만 수정된 페이지를 디스크로 보내버릴 수가 있기 때문이다.(isssue 세번째에 해당하는거지) 보내기 전에 UNDO를 해줘야한다.
UNDO: 완료되지 않았지만 일부 수정된 페이지를 원상복구
대부분 RDBMS는 언제든지 디스크에 수정된 페이지를 쓸 수 있도록 허용하기 때문에 UNDO는 필연적이다.
이전의 이미지로 현재 이미지를 대체
REDO: 커밋한 트랜잭션의 수정을 재반영하는 복구
대부분 RDBMS는 수정한 페이지를 커밋시점에 바로 디스크에 반영하지 않기 때문에 REDO는 필연적이다.
이후 이미지를 반영
UNDO와 REDO를 하는 법->LOG를 이용!
LOG: DBMS의 모든 변경사항을 기록하는 레코드들이다. 변경 이전의 이미지와 이후의 이미지를 모두 가지고 있다.
복구작업에 활용되므로 매우 안전하게 보관되어야 한다. 그래서 느린 함수를 쓴다.
issue! 로그쓰기(commit operation)의 성능을 높이는 법?
그룹 커밋 대기시간을 잘 정해서 한꺼번에 처리한다. 디스크 출력 횟수가 줄어들기 때문에 속도가 빨라진다.
결론: 어차피 DBMS가 알아서 동시에 하면 하나는 롤백해서 교착상태 처리하는데 왜 알아야하냐면,
DBMS마다 정책에 약간씩 다르고 성능이 안좋을때 그 원인과 대처(로그성능,교착횟수)를 할 수 있다.
또한, 로그보존의 중요성을 알아서 사고를 예방한다.
| 트랜잭션-동시성제어,회복 (0) | 2022.10.03 |
|---|---|
| Issue: 오라클 노트북 두 개에 설치해서 db 공유 (IP의 이해) (0) | 2020.01.02 |
| Index(인덱스) (0) | 2019.12.17 |
| NoSQL (0) | 2019.12.10 |
| 정규화 (0) | 2019.12.10 |