*hadoop 2.0 기준*
#빅데이터 청년인재 2기
#부산정보산업진흥원 하둡기반 빅데이터 처리
# https://www.slideshare.net/KeeyongHan/hadoop-introduction-10
사전지식
빅데이터 분석 프로세스

RDBMS와 NRDBMS의 차이
RDBMS)관계형 데이터베이스다. 그래서 관계가 깨지면 의미가 없어지므로 데이터 무결성이 중요하고, 무결성을 위해서 스키마로 데이터 입력을 거르는 것이다. 하지만 이렇게 하면 입력되지 않는 데이터가 발생한다. 대표적 문법으로 sql
NRDBMS)비관계형 데이터베이스다. 위와 다르게 스키마가 없다. 예를 들어서, char의 길이를 10까지 할당할 수 있을 때 길이11의 char가 들어오면 할당 가능 길이를 11로 동적으로 바꿔준다(?). 하지만, 기존 데이터에서 수정을 하려면 모든 데이터를 다시 만들어야해서 (?) 사용성이 떨어진다. 대표적 문법으로 Nosql(Not only sql)
하둡은 NRDBMS를 기반으로 한다.
텍스트 데이터 위주였던 과거와 달리, 이미지와 영상과 같은 비정형 데이터들이 급격히 증가하기 때문에 그것을 처리하는 것이 많이 연구되고 있다.
분산파일시스템
컴퓨터 네트워크를 통해 공유하는 여러 호스트 컴퓨터의 파일에 접근할 수 있게 하는 파일 시스템이다.
네트워크를 통해 접근하는 파일들은 프로그램과 사용자의 하나의 로컬 디스크에 있는 파일처럼 다룰 수 있다.
즉, 서버증설시 스케일아웃이 되는데
스케일아웃은 저렴한 서버를 여러대 쓰기 때문에 비용이 저렴하고, 장애가 생기더라도 전체가 마비되지 않는다.
하지만, 분산해서 처리하기 때문에 관리 편의성이 떨어진다. (병렬적인 처리:웹 앱, 분산처리 등에 쓰임)
스케일업은 하나의 서버를 비싼 것으로 맞춰두고 더 필요하면 더 좋은 하드웨어를 계속 달아가는 것이다. 관리에는 편하지만 비용증가의 부담이 크고 확장에는 한계가 있다. 또한, 일부가 마비되면 전체가 마비될 수 있다.

일괄처리방식(batch),실시간 시스템
일괄처리방식) 일정 기간마다 주기적으로 한꺼번에 업무 처리...Hadoop ..why?)
실시간시스템) 작업 수행이 요청되었을 때, 이를 제한된 시간안에 처리해 결과를 내주는 것
소개

아파치 하둡은 대량의 데이터를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 프리웨어 자바 소프트웨어 프레임워크이다. 분산처리 시스템인 구글 파일 시스템을 대체할 수 있는 하둡 분산 파일 시스템(HDFS)과 분산처리시스템(MapReduce)를 구현한 것이다.
배경
2006년 야후에서 일하던 더그 커팅이 구글 분산파일시스템에 대응하는 무료 라이브러리를 개발하고자 했고, 개발된 이후 아파치 재단으로 넘어가 관리되는 중이다.
구조

+namenode~datanode부분 글씨 너무 작아서...
->통신으로 3초마다 heartbeat 체크. 에러나면 그 노드 버리고 다른 노드로 블록 복사한다.

클라이언트가 파일을 쓰려면, 먼저 파일을 로컬에 저장한다.
만약 파일크기가 정했던 블록 크기를 넘으면 Namenode를 만나고, Namenode는 블록이 저장될 시작위치와 간격(Datanode사이의)을 클라이언트에게 전달함. 클라이언트는 받은 데이터노드 첫부분부터 차례로 저장되고, 이 과정을 replication pipelining이라 함.
클라이언트가 파일을 읽으려면, Namenode에게서 블록ID를 받아내서 읽는다. (블록 크기 넘으면 ID를 여러개 받는다)
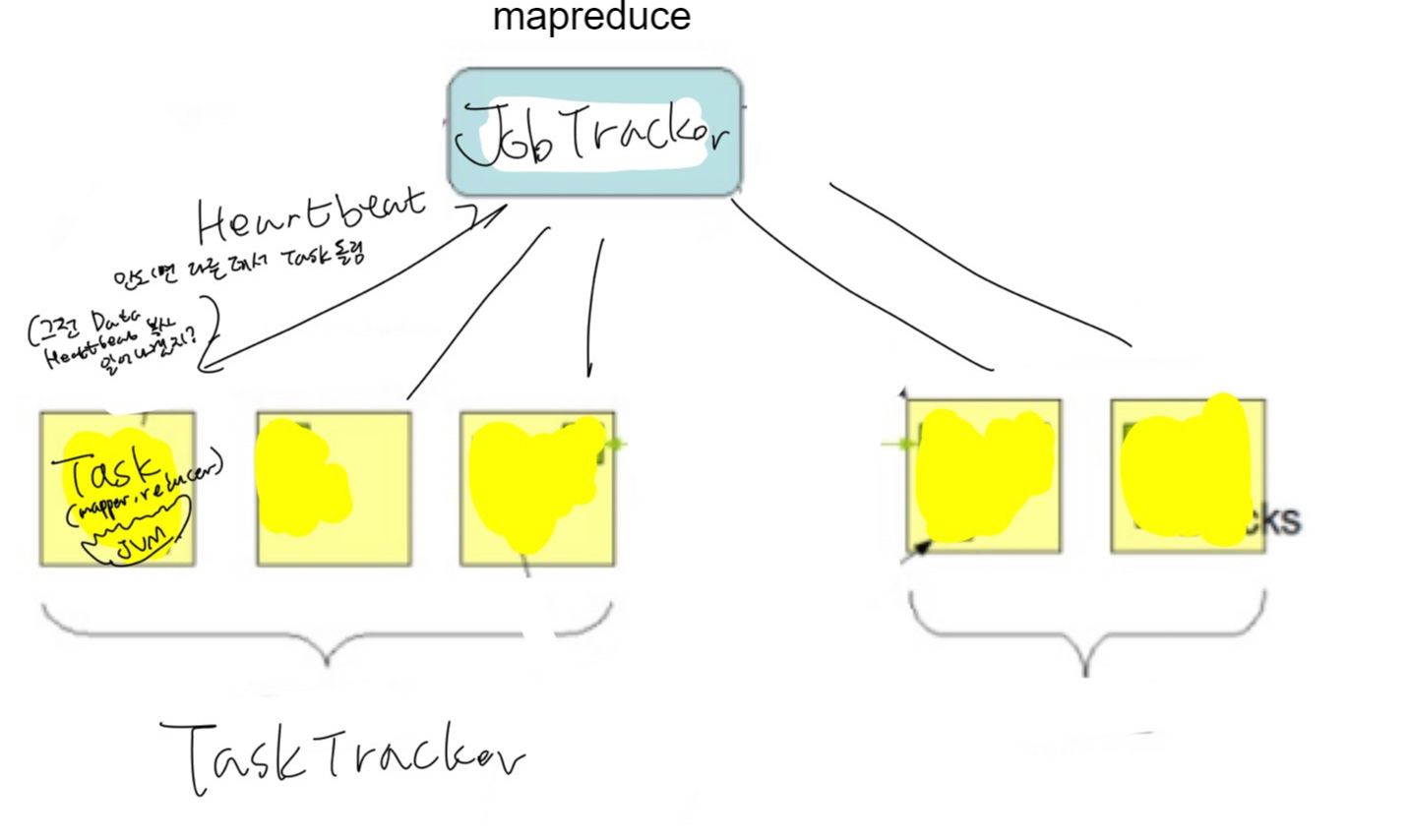
클라이언트가 하둡 잡 실행을 요청하면 하나의 잡 요청(맵리듀스코드 jar파일,입력위치,출력위치 등)을 JobTracker가 받고, 그
매퍼와 리듀스들을 TaskTracker에서 나누어준다.
이 과정을 하둡 웹 인터페이스로 확인할 수도 있다.

분산처리방식, 연속적인 작업을 나눠서 처리한다는 것부터 작업의 부분 부분이 서로 종속성이 없다는 것을 뜻한다.
그 대표적인 경우를 txt파일에서 어떤 단어의 카운트를 하는 것이라고 할 수 있다.
txt파일에서 서로 연관성이 없기 때문에 파일을 나눠 가지고 각각의 카운트를 한 뒤에 취합해서 총 합을 구해주면 된다.
여기서, 각각의 카운트를 하는 과정:맵리듀스의 매퍼 역할
총 합을 구하는 과정: 맵리듀스의 리듀스 역할
위의 그림이 일련의 과정이다. 왼쪽에서 오른쪽으로 갈수록 맵의 크기가 작아지므로, 맵리듀스라고 부른다.
맵리듀스 알고리즘은 가장 단순하게 만들어야한다. 그래야 수많은 서버에 흩어서 병렬로 처리할 수 있기 때문이다. 처리의 순서가 중요하다든지 실패했을때 다시하려면 몇단계 전으로 돌아가야 하는 상황은 있어서 안된다. 즉, 기준이 되는 값은 하나여야 한다.(이 말 매우 격공...알고리즘 풀 때 자꾸 예외에서 걸리는걸 느끼고 모든 경우를 고려하려면 단순해야 한다는걸 느낀 적이 있지)
자세한 설명은 아래 링크를..
맵/리듀스 (Map/Reduce) 이해하기
빅데이터를 접하기 시작하면서 자주듣게 되는 용어가 있습니다. 맵/리듀스 라는 용어인데요, MR이라고도 많이 쓰구요, 빅데이터 처리에는 늘 맵리듀스 개념이 들어가죠. 그럼, 빅데이터 처리의 기본이되는 맵리듀..
cskstory.tistory.com
구성
-HDFS (공통 패키지)
-MaReduce (공통 패키지)
-OS level abstraction (공통 패키지)
-하둡 에코시스템(관련 패키지)
-Jar file
-하둡 구동 스크립트
확장
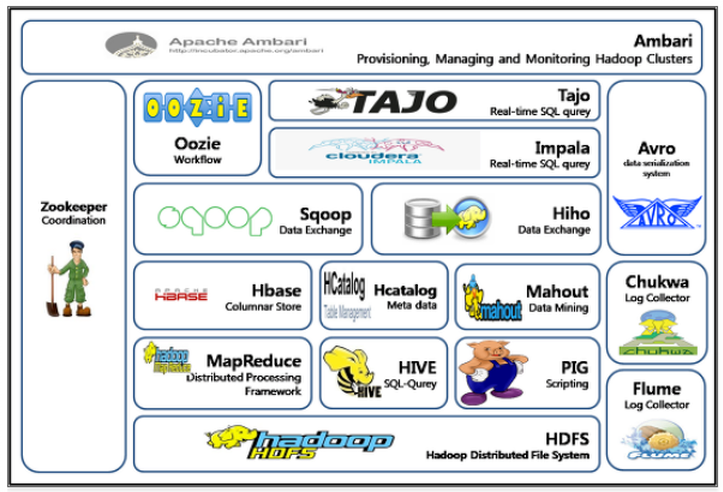
취사선택해서 아키텍쳐 구성하면 된다.(대신 릴리즈 호환성이 문제될 수 있으니 주의!)
장점,쓰이는 곳
-오프라인 배치 프로세싱에 최적화
-소수의 비싼 서버보다 다수의 저렴한 서버 이용 가능
-데이터의 지역성을 최대한 이용함
-병렬도 높은 처리: Text Grep,Web Crawling..
-로그분석
-머신러닝:Search Ranking..
단점,주의할 점
-소규모이거나 대용량(페타바이트급) 처리가 필요하지 않으면 옮길 이유 없음
-스킬셋으로 가진 사람 드물고 서포트 부실
-추가는 가능하지만 수정은 파일전체 새로 써야함 (그래서 상용으로는 못쓰고 분석,시각화로만 쓴다)
-실시간 처리 불가
이 기술에 관한 고찰
-SPARK와의 비교
스트리밍 데이터 처리 가능과 불가능의 차이. 하지만 스파크도 결국 하둡 파일시스템을 쓰고 각각 다른 것이지
어느 것이 좋다고 비교할 수 없다. 스파크는 ram에서 돌리고 하둡은 애초에 ram에 올리기 너무 커서 느려도 디스크에서(?) 작업하되 병렬처리를 하는 것이기 때문이다. 매우매우 크지 않으면 스파크를 쓰는 것이 유연하다고 생각이 든다.
데이터스택스(DataStax) 커뮤니티 관리자 스콧 헐맨 역시 "막대한 데이터를 포함한 대규모 분석은 앞으로도 계속 사용될 것이므로 일괄 처리는 사라지지 않을 것"이라면서, "스트리밍 분석에 대한 관심도 크지만 이 추세가 빅데이터의 미래에 미칠 영향에 대해 판단하기는 너무 이르다"고 말했다.
간단히 말해 스트리밍 분석(streaming analytics)은 '추가'일뿐, '양자 택일'의 문제가 아니다. 따라서 하둡과 같은 일괄 처리 지향 시스템을 시장에서 몰아내는 것이 아니라 보완하는 기술이 될 가능성이 높다.
-버전 1과의 비교
노드 다 올라오는거 확인하고 env파일 하나하나 안써도 되는거
'Skill > ETC' 카테고리의 다른 글
| 오픈소스 AI 온라인 교육 과정 [공개SW의 이해] (0) | 2020.04.14 |
|---|---|
| 깃허브 필수 내용 (0) | 2020.01.22 |