(1)프로세스 생성
What? 프로세스를 생성하는 방법은 부모프로세스가 자식프로세스를 낳는 것이다.
즉, 프로세스를 복제시키는 것이다.
How? 리눅스에서는 fork()함수를 호출해서 생성한다
code,data,stack+pc까지 복제해서 생성된다.
다음에 exec()함수를 호출해 새로운 프로그램을 올린다.
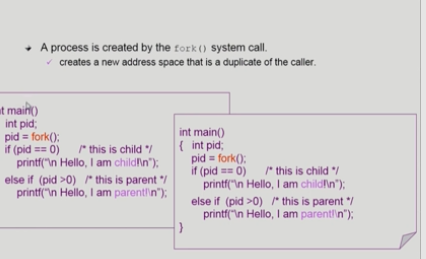
main부터 코드 실행하다가 fork (시스템콜,운영체제 필요)만나면 프로세스 하나 만들고 아무 일 없듯이 다시 아래 코드 실행한다.자식은 문맥을 복사했기 때문에 부모가 pc가 어디에 멈춰있는지 알아서 그 다음부터 실행한다.
즉, 자식은 if부터 시작한다는 말!(물론 fork반환은 각각 다르게 리턴되서 각자 실행하는 코드분기 다르다)
+cpu는 한번에 하나 프로세스인데 동시에 실행된다고? 스레드가 아닌데?
Why?
1.fork 전의 리소스(간단히 variable이라고 함)를 자식프로세스가 복사해 가지는 것인데, 리소스자체가 많으면 무거워지는 단점이 있지만(그래서 쓰레드가 나온걸로 알고 있습니다), 자식프로세스와 부모프로세스간 또는 자식프로세스간의 통신을 위해서 IPC의 동일한 키값을 갖기 위해서는 이것만큼 쉬운 방법이 없다. 직접 멀티 프로세스 프로그램을 해 보시면 느낄 수 있다고 한다.
2.동일한 프로세스의 여러 인스턴스를 매우 효율적으로 만들 수 있다. 예를 들어 웹 서버에 여러 클라이언트가 동일한 프로세스를 여러 개 제공 할 수 있습니다. 다른 프로세스를 생성하는 비용이 현재 프로세스를 복제하는 비용보다 훨씬 큰 경우는 스레드를 사용하지만 공유자원때문에 오류가 생길 확률이 높아진다.
+exec라는 시스템콜도 있지만 걔는 완전히 새로운 프로세스를 실행하는거다.
exec()라는 함수 호출 뒤의 코드는 실행불가능하다.
+wait()은 자식프세가 끝날때까지 기다려줌. sleep으로 잠들어있는다.기존과 다르게 부모-자식이 원래 프로세스 사이의 모양답게 경쟁이었는데 잠시 협력으로 모양이 변함.
+exit()
자발적 종료:컴파일러가 위치를 잡아줌. 스스로 종료
비자발적: 프세법칙이 부모보다 자식이 먼저 죽는거랬다. 부모가 kill같은 사용자로부터 멈춰짐을 당하면 함수 타고 내려가서 자식들 다 죽이고 자신도 죽음->근데 독립적인데 어케 말함?아, 트리형태로 저장이랬지
혹은 부모가 자식이 자원 너무 많이 써서 죽이는 경우. 프세 우선순위가 부모인갑다..
프로세스 원칙적으로 독립적(지 변수 지만 봄.자신만의 주소공간 가짐).하지만 가끔 협력해야하는 경우 두가지 방법 씀.
1.쉐어드 메모리(면접쓰):물리적으로 변수 공유(커널한테 미리 말해야됨)
2.메시지 통신:필요한 것 커널통해서 메시지로 서로 전달
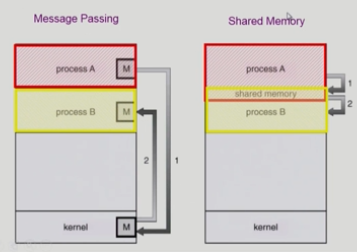
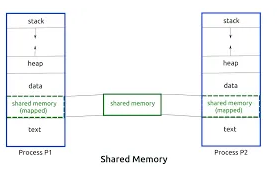
~스레드간의 협력도 기대해라~
프로세스들 보면 cpu만 주루룩(cpu burst) 쓰는게 많은 프로세스가 있고
IO만 주루룩(IOburst) 쓰는게 더 많은 프로세스가 있는데 이 둘이 교차 됨.
근데 사용자가 더 체감크니 IO프로세스에 좀 더 자원 줌.
그래서 CPU 스케줄러&디스패쳐 필요!
스케줄러는 뭐로 되있니?하드?소프? -> 운체 안에 코드로 있다
스케줄러가 결정을 내리면 디스패쳐가 실질적으로 문맥교환 도와주는거임
그래서 그게 언제 어떻게 적용되는데??

1은 나 cpu더 못써~io로 간다 해서 일어나는거
2는 한 애가 cpu 너무 오래 못쓰게 방지하려고 일어나는거
..
+선점형(뺏아서 바꿈),비선점형 있음(자진반납으로 바꿈)
(2)CPU스케줄링
2가지 이슈로 나뉜다.
1.다음에 누구에게 줄건지 2.강제로 할건지 끝나면 할건지
->현대는 선점형!
5가지로 성능을 평가할 수 있다.
1. cpu사용량:주방장이 놀지않고 일하는 비율
2.대기시간:밥먹는 시간말고 기다리는 시간
3.소요시간:들어왔다가 나가기까지
4.처리한 양:손님 얼마나 받았냐
5.응답시간: 첫 밥 먹기까지 걸린시간.중요. 초반에 단무지라도 주며 기다려야함.
그래서, 이런 종류들이 있다.(어디에 쓰면 좋을지랑 예제 하나 풀어보며 해보자)
1.FCFS: 온 순서대로. 비선점
앞에 긴거오면 다른 프로세스들 입장에서 겪는 대기시간이
길어짐 (waiting시간 증가)
고민해보자..공평성이 중요할 때 좋을듯!티켓팅
그럼 짧은거 먼저 앞으로 땡겨올까?
2.SJF:짧은거 먼저
nonpre,pre 다 있는데
pre는 스케줄 되있다가도 중간에 더 짧은애 오면 뺏음(참고로 계속 기준은 앞으로 더 써야하는 시간, 즉
남은 시간이다). 뺏는거라 대기 시간은 더 짧아짐
화장실생각! 대기가 치명적일떄!
+근데 더 짧은애 와도 강제없이 기다리면 그게 그냥 fcfs아닌가?

ㄴㄴ!계산해보면 뭔 차인지 안다. 먼저 온 애가 길어서 일단 실행중일때
큐에 쌓여있으면 그 중에서 스케줄링 하는거임.
->하지만 기아현상 발생!긴거는 영원히 못먹을수도..
꼭 대기중에 자기보다 짧은애만 들어오는 경우!
->실제cpu얼마나 잡을지 예측을 못하지만 예측공식(예전거 토대로) 있긴함
ㄴ왜하는거? 이미 계산되있는거 아녔나?->예측하고 들어왔는데 인터럽트 등으로 더 길어졌을때
본래 의도대로 가장 먼저 있는게 아니게 되니..예측을 사용하는 거임
3.우선순위큐:우선순위 젤 높은 애 한테 줄래. 우선순위는 다양하게 정의.
pre,nonpre.
사실 sjf도 결국 cpu타임이 기준인 우선순위큐임.
->그래서 마찬가지로 aging이라는 현상발생..
오래기다리면 순위높여주는걸로!
4.라운드로빈:가장 현대적!할당시간 세팅해서 줬다가 뺏고 다시 주고...
->공평해서 기아현상 ㄴㄴ!쓸 시간 예측도 불필요!
프세 길면 퀀텀도 길게 줌. 하긴 안그러면 오버헤드 많이 붙어서 더 안좋을듯.
지나치게 퀀텀 짧을때의 예시기도 함.
+스케줄링으로도 모자라서 큐를 여러층으로 분리해서 더 최적화를 했다!
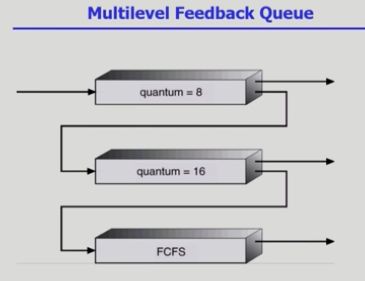
위의 큐일수록 우선순위 주고 아래일수록 안주는데 그렇게하면
starvation 생길 수 있으니 일단 위의 큐에 담기되 퀀텀내에 안끝나면
다음 순위 큐(퀀텀 김)로 밀려남.RR에서도 긴거일수록 퀀텀 길게 줬으니까.
큐마다 적용하는 스케줄링 다르다! 윗큐에 있다는건 빠르게 진행된단거니까
IO버스트가 짧게 자주 있거든, 그래서 거기엔 RR..

+Realtime스케줄러:데드라인 있어서 그 데드라인까지 각각 끝낼 수 있도록 먼저 스케줄링해두는 방식
하드-반드시 지켜야함
소프트-우선순위를 둠
+쓰레드 스케줄러:
로컬-운체가 일단 cpu를 프로세스에게 넘기면 그 뒤로 사용하는건 알아서 하도록 하는거
글로벌-운체가 쓰레드까지 스케줄링에 관여하는 것

지금까지 cpu하나 얘기였는데 여러개면 더 복잡~~
그리고 여기서 내가 더 주목할건
멀티프로세서랑 멀티프로세싱(앞에 위키백과 올린거)이 다르다는거!
멀티프로세싱은 cpu가 하나일수도 있지만 프로세서는 아니다.
성능비교 위해서 실제로 시뮬한다.(과제 있는듯)
'Basic > OS' 카테고리의 다른 글
| 가상메모리(Virtual Memory),페이지 교체 알고리즘 (2) | 2019.10.31 |
|---|---|
| 메모리 관리, 페이징, 세그멘테이션 (0) | 2019.10.26 |
| 데드락(Deadlock, 교착상태) (0) | 2019.10.18 |
| 프로세스 동기화 (0) | 2019.10.11 |
| 프로세스와 스케줄러, 스레드 (0) | 2019.09.30 |