메모리 관리
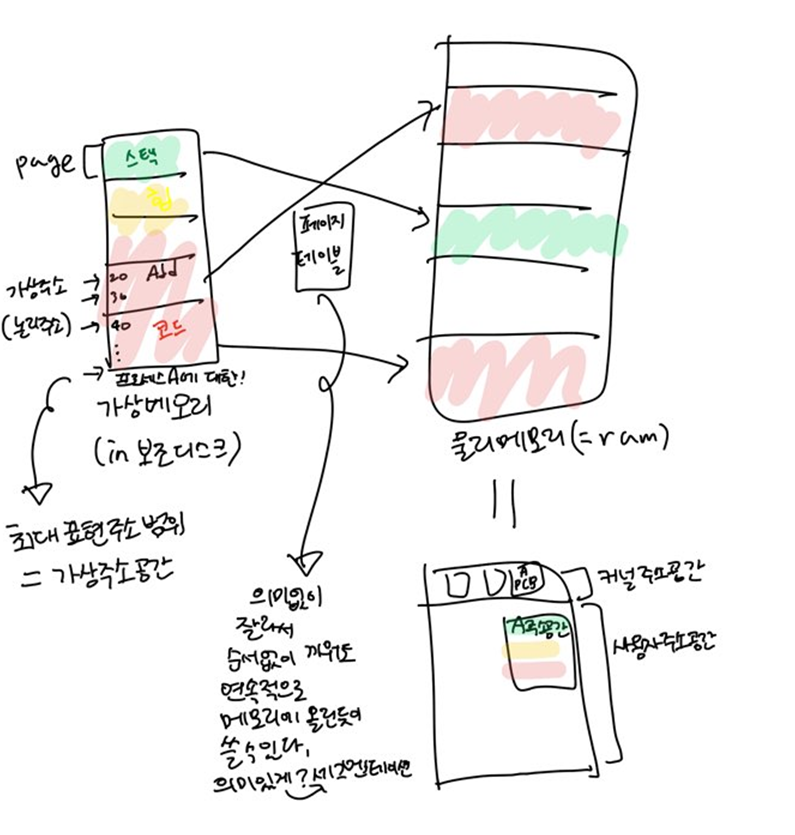
컴퓨터에는 여러가지 메모리가 있다. 먼저 요약해서 그 관계를 얘기하자면, Disk(보조기억장치)에서 실행파일을 가상메모리에 올리고 페이지로 나눈다. 탐색시 보조디스크가 아닌 논리메모리만 탐색해서 필요한 페이지를 물리메모리에 적재시키고, 페이지테이블을 사용해서 그 순서를 기억한다.
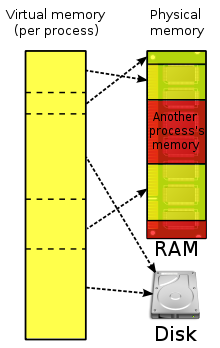
1.물리주소:주기억장치의 실제 저장위치 주소
2.가상메모리:보조기억장치를 주기억장치처럼 주소지정 가능하게 만든 저장공간 방법.
3.논리주소(가상주소):가상 메모리의 특정 위치에 배정된 주소 .각 프로세스 가상주소공간에서 0번지부터 시작. cpu가 보는 주소
4.가상주소공간:특정 프로세스에게 할당된 가상 주소의 영역
5.주소공간:특정 프로세스가 접근할 수 있는 메모리 주소의 영역
3.심볼릭 주소: 프로그래머 편의를 위한 변수
심볼릭 주소->컴파일->논리주소->주소바인딩->물리주소 과정을 거쳐서 메모리에 접근할 수 있다.
논리주소를 물리주소로 변환하는 바인딩 종류는 세 가지가 있다.

컴파일타임바인딩:
논리주소에서 정한 주소를 물리주소에서 그대로 사용하기 때문에, 프로그램 쓰면 빈공간을 찾아서 쓰지 않으므로 비효율적이다.
로드타임바인딩:
롸?//논리주소에서 계산해서 사용
런타임바인딩:
cpu를 뺏겨 메모리에서 나갔다가 들어올때 마다 주소가 바뀐다.(하드웨어 mmu가 지원이 필요하고 현대에 채택함)
cpu는 논리주소를 사용한다. 즉, cpu가 준 논리주소를 mmu가 물리주소로 변환을 해서 메모리에 접근하는 것이다. 이 과정을 바인딩이라고 한다.
cpu가 논리주소만 볼 수 밖에 없는 이유??
컴파일을 하고나서 실행파일을 cpu가 읽는데, 파일한 환경과 파일을 실행할 환경이 다른 경우, 실제 메모리값을 미리 알 수 없으므로 당연히 논리주소를 사용하여야 한다.
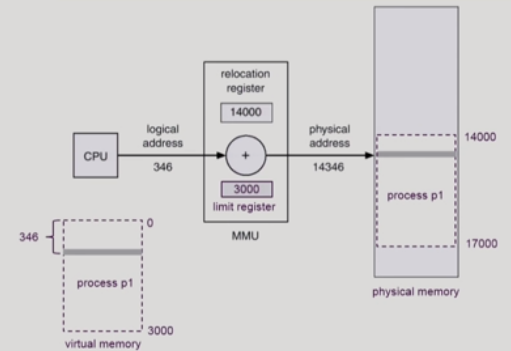
mmu는 하드웨어 장치로서,
접근하는 메모리 실제 주소=
가상주소공간의 0번쨰 논리주소에 해당하는 물리주소+cpu가 준 논리주소.
이때, 지정된 범위 벗어나는지 검사하는 소프트웨어 인터럽트가 존재한다.
주메모리에 접근해서 프로세스 주소공간이 배치된다.

-연속배치(각 프로세스가 메모리에 연속적으로 배치)
-불연속배치(하나의 프로세스가 메모리에 나눠져서 배치 됨,현대):페이징,세그멘테이션
-고정분할(사용자메모리 영역을 미리 파티션으로 나눠둠 ):페이징
-가변분할(미리 나눠두지 않고 들어오는대로 받아들임):세그멘테이션
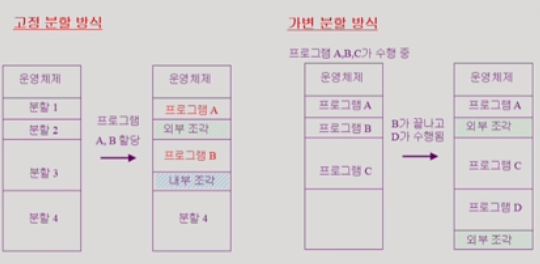
| 고정분할방식 | 가변분할방식 |
| 같은 크기든 다른 크기든 메모리를 미리 파티션으로 나눠둠 | 미리 나눠두지 않고 들어오는대로 배치한다 |
| 크기가 맞는 것이 나올때까지 건너뛰므로 외부단편화 발생 | 먼저 수행을 마친 프로세스가 나가서 중간에 외부단편화 발생 |
| 할당된 공간에 비해 필요한 공간이 작으면 내부단편화 발생 | 처음부터 필요한만큼 크기 할당받으므로 내부단편화는 없다 |
단편화 해결방법:(바인딩을 많이 해야되서 비용이 많이 들고 주소가 계속 바뀌므로 런타임바인딩이 지원되야 함)
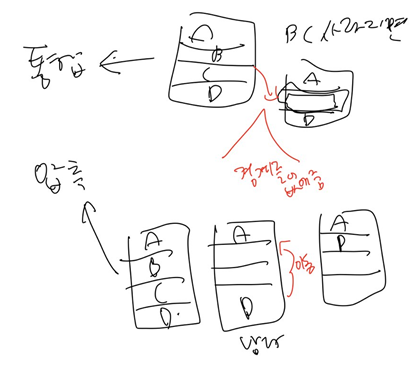
배치전략
1.first fit:사이즈가 n이상인 것중 처음 발견되는 것
2.best fit:가장 갭이 작은 홀로
3.worst fit: 가장 큰 홀로(장기적으로 안좋다..더 큰 프로세스 왔을때 써야하는데..)
스와핑: 메모리에서 cpu우선순위 낮은 프로세스를 디스크로 쫓아내거나 불러오는 것.(중기스케줄러)
롸?//동적로딩(동적:필요할 때마다 쓴다 ,로딩: 메모리에 올리는 것):
개발자가 방어적인 코드(예외처리코드)처럼 자주 쓰지 않는 코드를 명시적으로 나타내서 필요할 때만 부름.
+어떤거?
동적링킹(링킹:내가 사용하는 라이브러리 등의 코드를 실행할 때 코드로 붙여주는 것 동적:필요할 때마다):
static linking-컴파일하면 내 코드에 그 코드들이 추가가 된다.
dynamic linking-파일로 라이브러리에 코드있고 그 주소로 가는 거만 저장해둬서 필요할 때 그 동작만 수행
ㄴ이래서 printf함수 입출력 함수 쓰면 오래 걸린다는거구나..
오버레이:
페이징
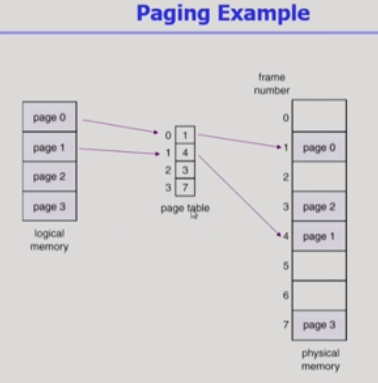
What?
주메모리에서 사용하기 위해 2차 기억 장치로부터 데이터를 저장하고 검색하는 메모리 관리 기법이다.
How?
가상메모리를 모두 같은 크기의 페이지로 나누고 페이지는 같은 크기로 주메모리로부터 프레임을 할당받아서 적재된다.
인덱스로 바로 접근할 수 있는 페이지 테이블을 가지고 있다.
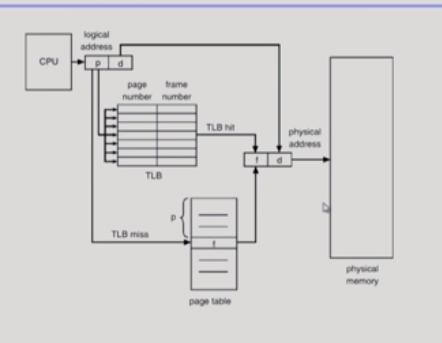
페이지 주소와 offset으로 이루어진 키값 테이블.
p,d => p페이지 d번째라는 뜻
(페이지 테이블에서 p에 해당하는 물리주소 f를 찾아서 d만큼 떨어진 실제주소를 찾는다.)
Where?
캐시에 넣기엔 너무 크고,에 넣기엔 빠르게 주소변환 해야하는데 부적절해서 메모리에 넣는다...
즉,
주메모리에 2번 접근한다<-속도 높이기 위해서 TLB(캐시역할하는 테이블,메인메모리와 cpu사이 하드웨어로 존재) 쓴다.
32bit에선 주소를 2^32까지 표현할 수 있다. 2^30은G이므로 4G.
이때, 주소 하나당 한 페이지인데 한 페이지는 최대 4K이므로
프로그램은 최대 4G/4K=100만개의 페이지로 구성되어 있다.
페이지테이블의 엔트리가 4바이트이므로 프로세스마다 4메가의 페이지테이블이 필요하게 되어 메모리 공간이 낭비된다.
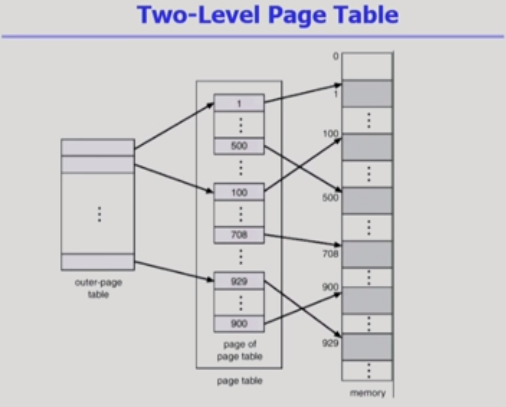
2단계 페이지 테이블!
속도는 줄어들지 않아도
공간은 줄어든다.
->비효율->2단계로 가자~~
->근데 2단계 페이지테이블까진 몬하게따 힘들다
프로세스가 공유하는 코드 있으면 메모리에 하나만 올림.
(shared code=pure code)<-read only여야함. ipc통신의 쉐어드 메모리랑은 다른 것
세그멘테이션
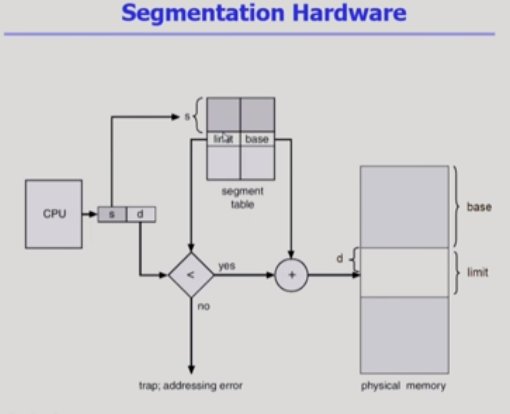
What?
주메모리에서 사용하기 위해 2차 기억 장치로부터 데이터를 저장하고 검색하는 메모리 관리 기법이다.
How?
가상메모리를 의미적인 세그먼트로 나눈다.
(sharing하거나protection)
페이징은 크기 고정되어있지만 세그먼트는 가변적이므로 프로세스 초기위치 말고도 limit이 필요하다.limit 연산 시 할당크기 넘는다하면
할당 안함.
| 페이징 | 세그멘테이션 |
|
엔트리에 권한값을 부여해 페이지마다 read only/write등을 달아줘야한다. |
의미단위라 그런 문제는 없고 |
| allocation문제가 발생하지 않는다. | allocation문제가 발생할 수 있다. |
| 테이블에 의한 메모리 낭비는 페이징이 더 크다. | |
| 페이징은 갯수 알 수 있는데 | 갯수 추측 못함. |
|
내부단편화 있고(페이지보다 작으면 무조건 발생) 외부단편화는 불연속이라서 없다 |
내부단편화는 없지만 외부단편화는 있다 |
+새그맨트~페이지 섞어서 쓰기도..
+프로세스의 메모리 접근시 cpu가 바로 접근 가능. but IO장치 접근할때만 커널도움 받음.
'Basic > OS' 카테고리의 다른 글
| 가상메모리(Virtual Memory),페이지 교체 알고리즘 (2) | 2019.10.31 |
|---|---|
| 데드락(Deadlock, 교착상태) (0) | 2019.10.18 |
| 프로세스 동기화 (0) | 2019.10.11 |
| 프로그램 생성과 종료,cpu 스케줄링 (0) | 2019.10.04 |
| 프로세스와 스케줄러, 스레드 (0) | 2019.09.30 |