*아이패드로 정리한 pdf 파일*
'Basic > Network' 카테고리의 다른 글
| http와 https의 차이 (0) | 2020.02.06 |
|---|---|
| TCP/IP와 UDP의 차이 (1) | 2020.02.05 |
| TCP 3 way handshake (0) | 2020.02.03 |
| 웹 통신 흐름 (0) | 2020.02.01 |
| Http 메소드 (Get,Post,Delete,Header..) (0) | 2020.01.31 |
*아이패드로 정리한 pdf 파일*
| http와 https의 차이 (0) | 2020.02.06 |
|---|---|
| TCP/IP와 UDP의 차이 (1) | 2020.02.05 |
| TCP 3 way handshake (0) | 2020.02.03 |
| 웹 통신 흐름 (0) | 2020.02.01 |
| Http 메소드 (Get,Post,Delete,Header..) (0) | 2020.01.31 |
목표:
내 노트북에 오라클 서버를 설치하고 넣은 데이터를 멀리 떨어진 팀원이 데이터 조회가 가능하도록 만들기.
상황:
내 노트북에 오라클 설치를 먼저 했고, 간단한 데이터 입력 및 조회가 되는 것까지 확인.
팀원 노트북에서도 같은 과정을 수행.
문제:
원격접속을 하려고 할 때 no listener란 error가 발생하거나 network adapter를 찾을 수 없다는 error가 발생함.
원인:
사설IP를 사용하면서 포트포워딩 없이 노트북의 포트에 접근하려고 시도해서 서버를 찾을 수가 없었다.
사설IP,공인IP,유동IP,고정IP의 개념이해가 부족했다.
해결:
1. 포트포워딩orDMZ를 한다
2. aws를 사용한다(1도 성공하긴 했지만, 집 컴퓨터를 서버로 내내 돌리기에는 유동ip 성격상 ip가 바뀌거나, 컴퓨터가 꺼질 상황을 염려하여 aws를 사용하기로 했다.)
해결하게 된 추론:
1. 호스트 접속시 error: no listener.
2. 각 컴퓨터 listener 켜져있는지 services.msc로 확인
3.listener파일이 제대로 설정되어 있는지 확인
4.ping test로 각 컴퓨터 연결되는지 확인
이때,listener 파일에 있는 ip와 ping test가 가능한 ip가 다른걸 보고 사설ip와 공인ip의 차이를 알게 되었다.
5.공인ip와 사설ip를 연결해주는 방법, 포트포워딩을 찾게 되었다.
6.포트포워딩보다 간단한 DMZ 설정을 해보았다.
7. 다시 시도, 해결!
공부한 내용:
IP는 컴퓨터의 주소라고 할 수 있다. 아파트에 비유하자면, 부산광역시 해운대구 우동 00 센텀0로 00,00동 0000호라는 주소가 있다고 치자. 여기서, 공인IP는 '부산~~00로00'까지이다. 사설IP는 '00동 0000호'이다. 원격접속을 위해서 쳐야할 주소란에 나는 00,0000로만 계속 알려준 것이다. 친구에게 찾아와라고 자기 집 주소를 알려줄 때, 어느동네 무슨아파트인지 얘기도 안해주고 00동 0000호라고만 얘기하면 어떻게 찾아올 수 있을까?

네이버에 '내ip'를 검색해서 나온 ip는 공인ip이고 ipconfig로 검색해서 본 wifi ipv4는 사설ip이다.
그렇다고 공인ip만 알면 되는건 아니다. 공유기(NAT)까지만 찾아올 수 있고, 내 컴퓨터까지 도달할 수 없다면 소용이 없다.
이때 필요한 것이 '포트포워딩'이다. 위 그림에서 (C)에서 (A)의 1521포트로 접속하기 위해서 (A)와 연결된 공유기에
"1521포트를 요청하면 A컴퓨터의 1521포트로 연결해줘"라고 설정하는 것이다. 방법은 생각보다 간단하므로 검색해서 찾아보면 된다. (자신 공인아이피로 접속을 하면 관리자 페이지가 뜨는데, 거기서 매핑을 해주면 된다. 모든 포트를 열어버려서 더 간단한 DMZ도 있으니 참고하자)
+고정IP란? ISP에서 제공받아서 특정 컴퓨터(기기의 MAC주소로)와 1:1로 매칭되는 IP. 즉, 사설IP고 뭐고 하나의 IP만 알면 세계 어디서든 접속이 가능하다. 유지비용이 비싸고, IP가 바뀌면 안되는 기업의 서버 설치에 사용된다. 그래서 도메인 서비스가 가능하다. 111.111.111.111->채니.com 요렇게
+유동IP란? ISP가 특정 대역을 가지고 있어서, 그 대역에 한해서 사용자에게 IP를 자동으로 뿌려주는 것. 즉, 하나의 IP에 대해 사용자가 계속 바뀐다는 것이다.
그 이후...
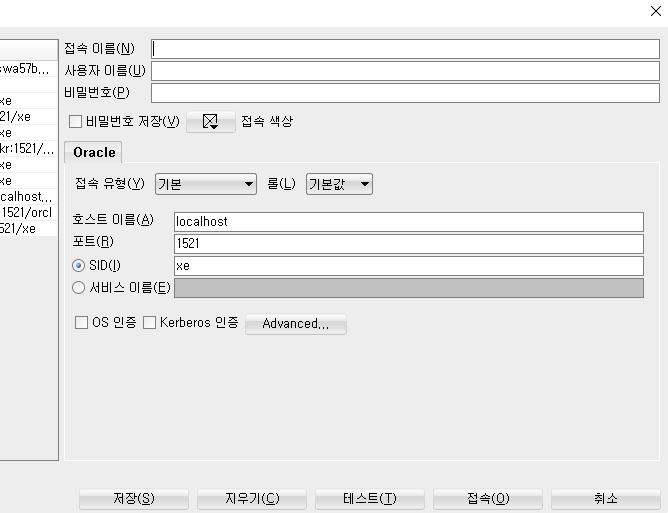
사용자이름,비밀번호 <-서버에서 생성한 아이디와 비밀번호
호스트이름 <-접속할 IP
포트 <-oracle은 보통 1521포트를 사용함.
SID <- 접속할 DB의 인스턴스 이름
이렇게 접속을 만들기 전에 tnsnames.ora 파일과 listener파일을 따로 설정해줘야한다. 오라클에서 네트워크를 통해 원격접속을 하려면 오라클 폴더의 설정파일을 수정해줘야하기 때문이다. (->https://oracle.tistory.com/87) 그 다음 DBlink를 설정해주면 DB를 공유할 수 있다!
+여담: 성공하긴 했지만, 집 컴퓨터를 서버로 내내 돌리기에는 유동ip 성격상 ip가 바뀌거나, 컴퓨터가 꺼질 상황을 염려하여 aws를 사용하기로 했다. aws를 사용하며 사용자ID만큼은 다르게 하려고 했지만, 이또한 dblink가 필요하고 이를 위해서 클라이언트+서버 프로그램 둘다 설치해야하기 때문에 아이디를 하나로 통일하기로 결정했다.
+그 외에 알게된 것..
+ftp(21). ssh(22),web(80),oracle(1521)..
+ping테스트로는 해당 주소가 네트워크에 연결되있는지만 확인 가능하지만 별도의 프로그램 설치를 통해
tnsping을 이용하면 특정포트가 열려있는지까지 확인이 가능하다.
+오라클xe설치로 서버를 먼저 설치하고 클라이언트 앱으로 sqldeveloper를 깔아서 쓰는 것이다.
내장된 sqlplus 클라이언트도 있다.
http://blog.naver.com/PostView.nhn?blogId=jyc8618&logNo=220163994820
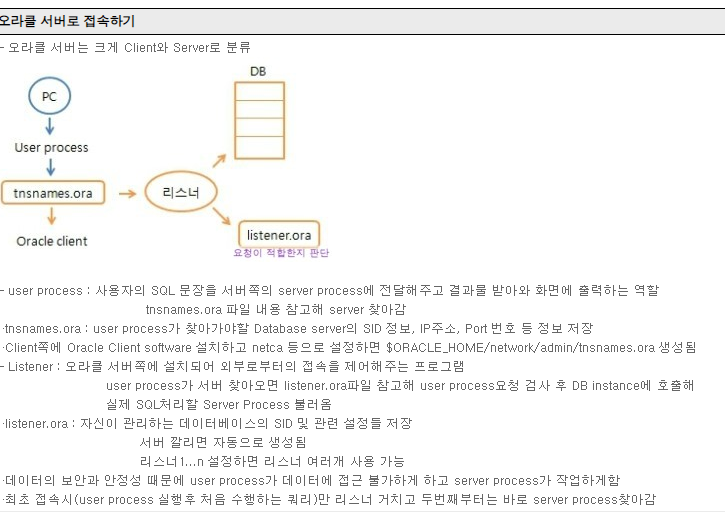
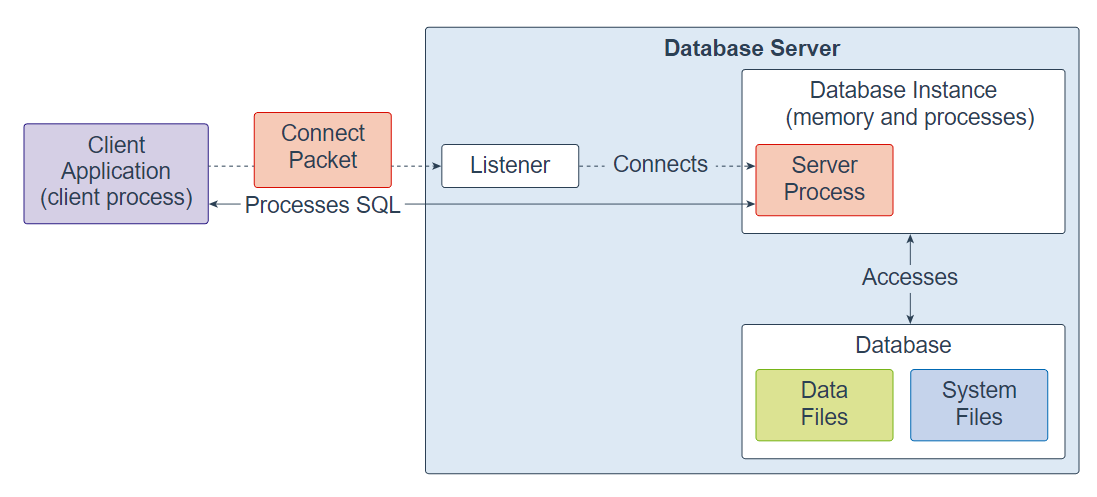
+서버를 이전하는 것= 마이그레이션
| 트랜잭션-동시성제어,회복 (0) | 2022.10.03 |
|---|---|
| 트랜잭션 (0) | 2020.01.30 |
| Index(인덱스) (0) | 2019.12.17 |
| NoSQL (0) | 2019.12.10 |
| 정규화 (0) | 2019.12.10 |
인덱스란?
검색연산을 빠르게 하기 위한 Key-Value자료구조이다.
ex)n개의 데이터가 저장되있을때, 특정 값 찾으려면 n개의 데이터 모두를 검색해야한다. 하지만, 값_value을 정렬하여 순서_key를 붙여두면 값을 찾을떄 순서를 이용해 바로 접근해서 모든 데이터를 확인하지 않아도 되므로 빠르다.
종류
-B-TREE(트리형태로 key-value를 저장)
-BITMAP(2차원 배열로 key-value를 저장)
생성과정
전체 테이블 스캔->정렬->Block에 기록
1)B-TREE
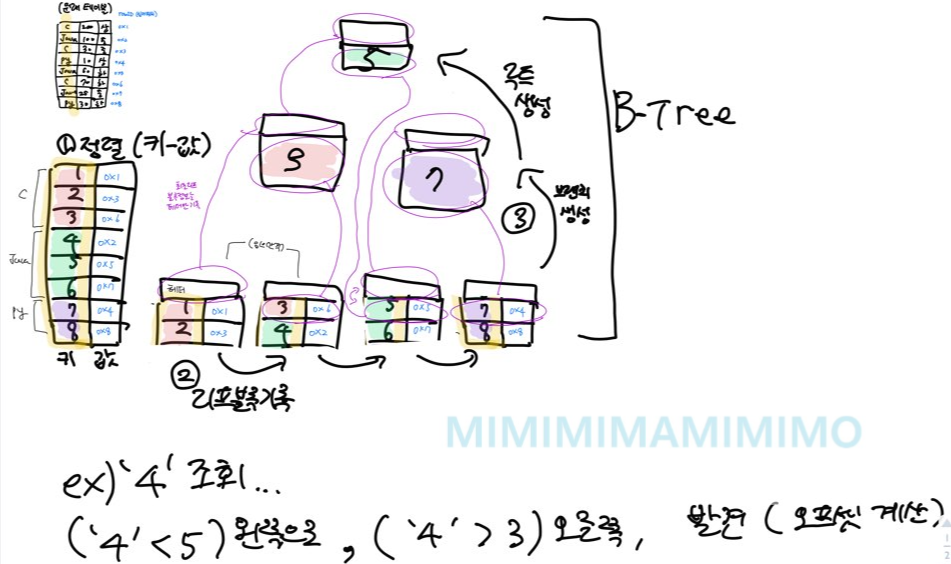
+키,로우
위를 보면 알 수 있듯이/
-best
칼럼이 추가되도 B-TREE를 저장해뒀으므로 새로 정렬이 일어나지 않으므로/ 실시간 처리에 효율적이다(거진logn)
-worst
하나의 리프블록의 중간값이 입력되면 split이 일어나므로/칼럼 값의 수정이 빈번하지 않은 곳에 쓴다.(trie떄 생각하자..)
2)BITMAP
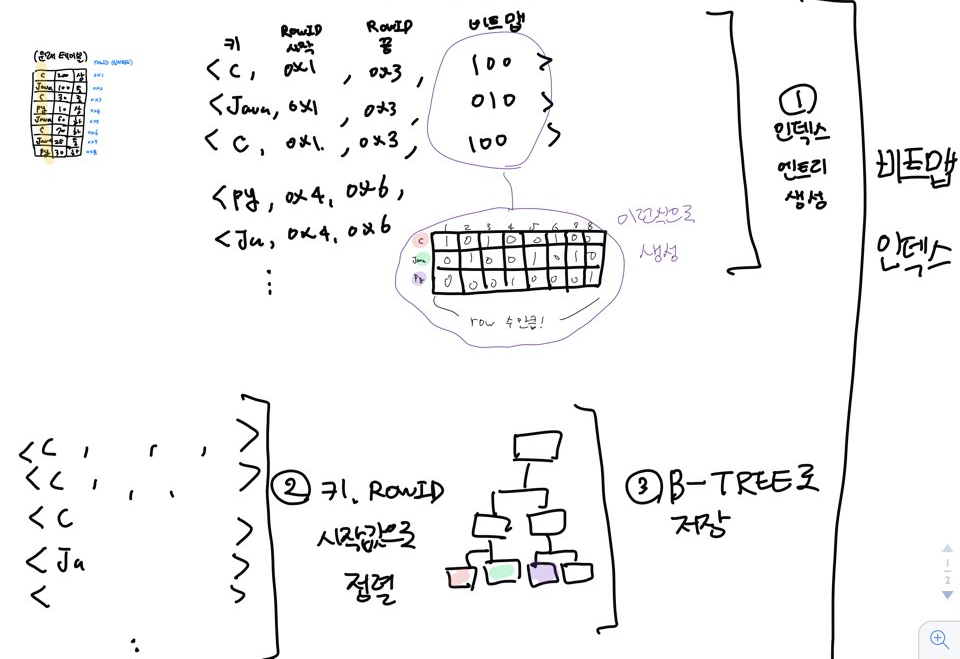
+함수지원으로 실제 로우주소 몰라도 상대주소로 계산이 가능
+1이 있는 값만 찾으면 된다
+키,로우스타트,로우엔드,비트맵
위를 보면 알 수 있듯이/
-best
비트연산을 사용하므로 빠르고 실제 칼럼값을 가지고 있지 않아도 되서 저장공간이 절약되므로/대량의 데이터를 한꺼번에 처리할 때 효율적이다.
-worst
칼럼 하나 추가되면 모든 테이블 바뀌어야므로 효율이 나빠지므로/ 맵의 칼럼 종류 수정이 적은 곳이 좋다.
..흠..이분법적으로 뭐는 시간이 좋고 뭐는 공간이 나쁘다 할 수 있는게 아니라 여로 요소를 생각해야하는구나
조회과정
사용자의 요청에 의해 서버프로세스가 메모리의 데이터베이스 버퍼캐시를 본다.
없으면 하드디스크의 데이터파일에서 data블록을 찾아 버퍼 캐시로 복사하고 사용자에게 값을 반환한다.
실습~~
실습
(https://itholic.github.io/database-index/)
인덱스 사용시 주의할 점!(http://www.dbguide.net/db.dbcmd=view&boardUid=13856&boardConfigUid=9&categoryUid=216&boardIdx=80&boardStep=1)
인덱스 선정은 테이블에 접근하는 모 든 경로를 수집하고 수집된 결과를 분석하여 종합적인 판단에 의해 결정하는 것이 바람직하다.
B-TREE
http://wiki.gurubee.net/pages/viewpage.action?pageId=1507450
BITMAP
http://wiki.gurubee.net/pages/viewpage.action?pageId=1507452
| 트랜잭션-동시성제어,회복 (0) | 2022.10.03 |
|---|---|
| 트랜잭션 (0) | 2020.01.30 |
| Issue: 오라클 노트북 두 개에 설치해서 db 공유 (IP의 이해) (0) | 2020.01.02 |
| NoSQL (0) | 2019.12.10 |
| 정규화 (0) | 2019.12.10 |
CAP관련 설명
https://www.slipp.net/wiki/pages/viewpage.action?pageId=19530140
5주차-mongodb - SLiPP 스터디 - SLiPP::위키
설치 http://docs.mongodb.org/manual/installation/ 잠깐! CAP 이론 NoSQL은 분산형 구조를 띠고 있기 때문에 분산 시스템의 특징을 그대로 반영하는데, 그 특성 중의 하나가 CAP 이론이다. 이 이론은 2002년 버클리대학의 Eric Brewer 교수에 의해 발표된 분산 컴퓨팅 이론으로, 분산 컴퓨팅 환경은 일관성(Consistency), 가용성(Availability), 분산 가용성(Partitioning) 세
www.slipp.net
*아이패드로 정리한 pdf 파일*
| 트랜잭션-동시성제어,회복 (0) | 2022.10.03 |
|---|---|
| 트랜잭션 (0) | 2020.01.30 |
| Issue: 오라클 노트북 두 개에 설치해서 db 공유 (IP의 이해) (0) | 2020.01.02 |
| Index(인덱스) (0) | 2019.12.17 |
| 정규화 (0) | 2019.12.10 |
참고) 데이터베이스 첫걸음, 기무라 메이지
정규형
칼럼을 정할 때 이상이 생기지 않도록 만드는 규칙
정규화
정규형을 만족하도록 릴레이션을 분해해나가는 것
아노말리
-삭제이상
200번학생이‘C123’ 과목을등록취소..200번학생의학년정보소실
-삽입이상
600번학생이2학년정보(투플)을삽입..불필요한정보(임시과목번호)를채워줘야함
-갱신이상
400번학생의학년을4->3로변경..4개의투플을모두갱신해야함
함수 종속
릴레이션이 변경되도 계속 지켜져야하는 의미적 관계(한 순간의 값으로 판단ㄴㄴ)
x(결정자)->y(종속자)
제1정규형: 하나의 셸에 복합적인 값을 포함하지 않는다
why? x에는 y가 대응하는 함수관계이기 때문에 기본키가 모든 열의 값을 하나로 특정할 수 있어야한다.

(1)처럼 칼럼을 추가->릴레이션 정의 변동이 많이 일어나서 성능 저하가 심함.
(2)->딩동댕
제2정규형: 제1을 만족하고, 기본키의 일부에만 종속하는 열이 없어야 한다 (==부분종속이 없어야한다)(기본키가 열이 하나라면 자동적으로 만족)
why? 아래를 먼저 보자.
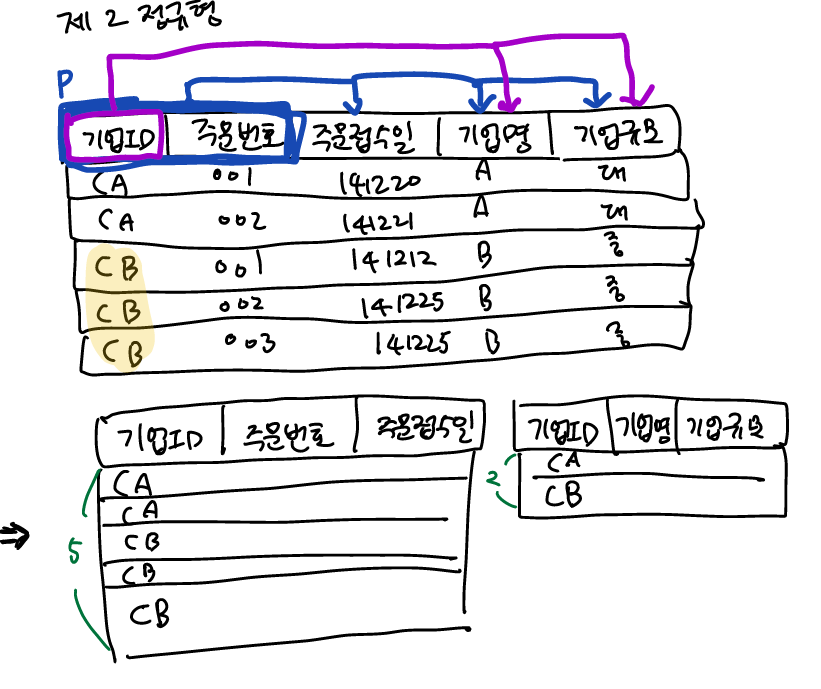
-기본키
cb,cb,cb가 중복되므로 [기업ID]만으론 기본키가 될 수 없다. 즉, [기업ID+주문번호]이다.
기본키를 정할 떈 의미적으로 거르고, 값으로 걸러서 정해야한다.
-존재하는 함수종속
[기업ID+주문번호]->[접수일]
[기업ID+주문번호]->[기업명]
[기업ID+주문번호]->[기업규모]
[기업ID]->[기업명]
[기업ID]->[기업규모]
여기서, 기본키의 일부인 [기업ID]에 종속되는 종속자 [기업명],[기업규모]가 있다.
[기업명]과 [기업규모]열의 입장에서 보면, [주문번호]열음 쓸데없는 정보일 뿐이다.
[주문번호] 열의 입장에서 보면, [기업규모]를 알지 못하면 데이터를 삽입할 수 없는 삽입이상이 생긴다. null허용은 썩 좋은 방법은 아니다.
그러므로, 기업ID만으로 기업명과 기업규모를 결정짓는 릴레이션으로 분해한다.
제3정규형: 제2를 만족하고, 기본키를 제외한 열에서 이행종속이 존재하지 않는다.
이행종속
기본키가 [a]일때, [b]->[c]라는 종속관계가 있으면 기본키 정의때문에 [a]->[b]가 성립되고, [a]->[b]->[c]가 되므로
[c]는 기본키[a]에 이행종속이다.
why?갱신이상이 여전히 존재하므로(참고로, 몇 정규화를 하면 무슨 이상은 완벽히 없어지고, 그런 경우는 없다. 단계가 높아질수록 이상이 생길 확률이 줄어드는 것 뿐이다). 아래를 보자.
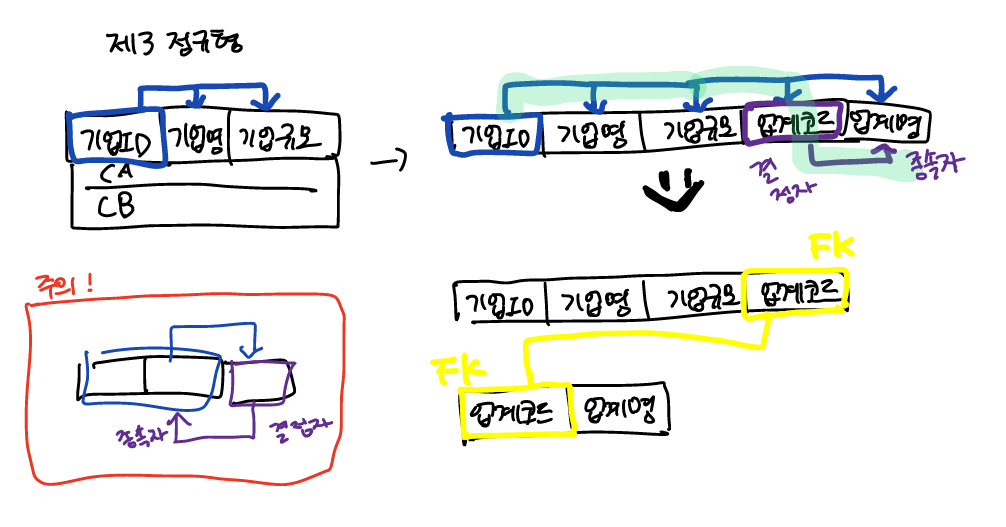
거래가 발생하지 않으면 기업의 업계코드와 업계명을 추가하고 싶어도 추가할 수 없다.
(ex거래한 업계는 석유,바이오와 했는데 업계종류를 화학도 추가하고 싶을떄..)
이런 경우, 업계코드와 업계명을 따로 빼서 분해한다.
주의 와 같은 경우는 이행종속이 아니다. 해당 종속관계의 종속자가 기본키이므로 제3정규형 정의와 관련없다.
BCNF: 릴레이션의 결정자가 모두 후보키여야만 한다
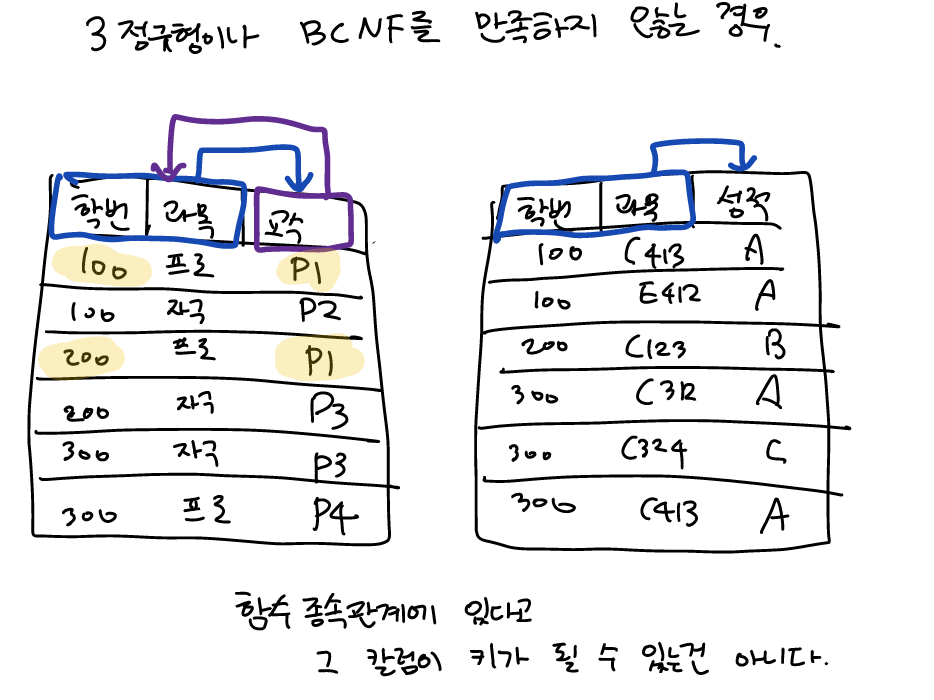
-존재하는 함수종속
[학번+과목]->[교수]
[교수]->[과목]
결정자는 [학번+과목],[교수] 총 두 가지가 존재한다.
[학번+과목]은 기본키이므로 후보키가 아니다.
[교수]는 키가 아니다. 그러므로 BCNF를 만족하지 않는다.
*제3을 만족하지 않는다고 실수할 수 있다. 교수와 과목은 이행종속이 아니다. 과목이 기본키이므로, 제3의 정의인 '기본키가 아닌 열이 기본키로부터 종속자'에 해당하지 않기 떄문이다.
정규화를 많이 하면 테이블 수가 늘어난다
->테이블 간의 관계성을 파악하기 힘들다
->ER다이어그램을 그린다.
정규화를 많이하면 테이블 수가 늘어난다
->조인을 할 확률이 높다
->성능이 낮아진다/대신, 아노말리는 적다
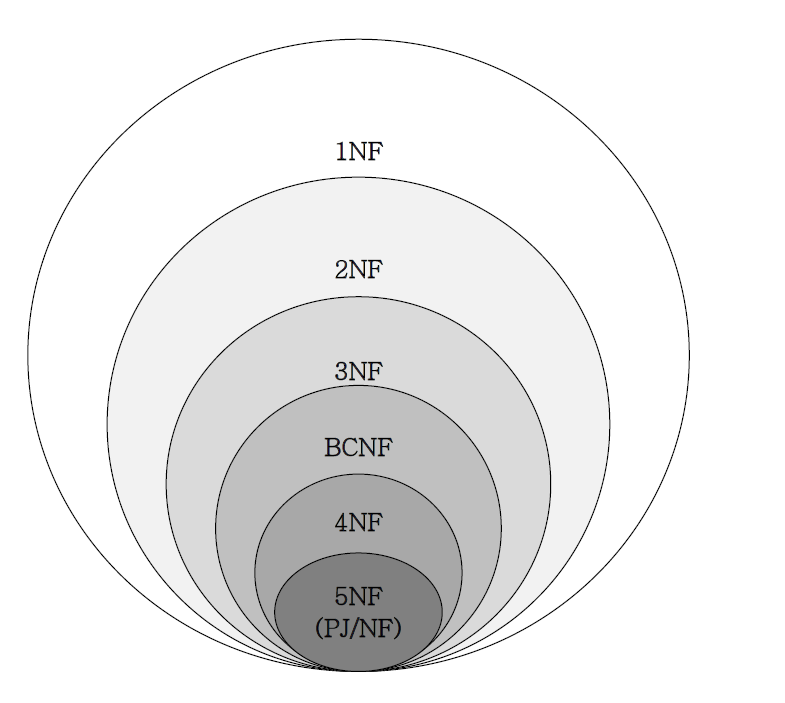
제5정규화까지 있지만 실무에선 제3정규화까지만 하면 된다
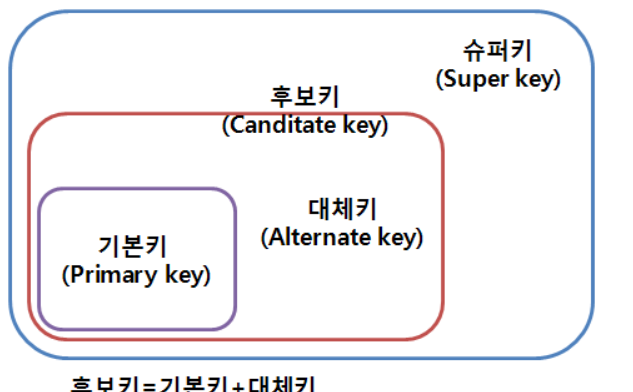
키의 종류와 관계
| 트랜잭션-동시성제어,회복 (0) | 2022.10.03 |
|---|---|
| 트랜잭션 (0) | 2020.01.30 |
| Issue: 오라클 노트북 두 개에 설치해서 db 공유 (IP의 이해) (0) | 2020.01.02 |
| Index(인덱스) (0) | 2019.12.17 |
| NoSQL (0) | 2019.12.10 |
*참고: http://web.mit.edu/rhel-doc/4/RH-DOCS/rhel-isa-ko-4/s1-memory-concepts.html#S2-MEMORY-VIRT-SIMPLE*
*디맨드 페이징을 쓴다는 가정하에 포스팅*
,실제 주기억장치보다 큰 메모리 영역을 제공하기 위해 운영체제가 제공하는 논리메모리이다.
보조기억장치에 존재하며, 프로세스의 주소공간 중에서 필요한 부분만 가지고 있다. (이전편 참고)
또한, 캐시의 기능을 하며(논리메모리만 검색하면 됨) 공유메모리를 가능하게 한다.(어떻게?)
이 어플리케이션의 기계 코드 용량은 10000 바이트라고 가정해봅시다. 또한 데이터 저장 및 입/출력 버퍼에 5000 바이트가 필요하다고 가정합니다. 이러한 경우 이 어플리케이션을 실행하기 위해서는 최소한 15000 바이트의 RAM이 필요합니다. 만일 1 바이트라도 부족하다면 이 어플리케이션을 실행할 수가 없습니다.
하지만 메모리 접근은 순차적이고 지역화되어 있다는 내용을 다시 생각해보십시오. 이러한 특성으로 때문에 이 어플리케이션을 실행하는데 필요한 메모리 용량은 15000 바이트 보다 훨씬 적습니다. 단독 기계 명령어를 실행하기 위해 필요한 메모리 접근 방식을 예를 들어 보겠습니다:
메모리에서 명령을 읽어옵니다.
명령어가 필요로하는 데이터를 메모리에서 읽어옵니다.
명령이 완료된 후 결과가 메모리에 다시 기록됩니다.
매번 메모리에 접근하는데 필요한 실제 바이트 수는 CPU 아키텍쳐 및 실제 명령어와 데이터 유형에 따라 달라집니다. 그러나 한 명령어를 실행하는데 각 메모리 접근 유형마다 100 바이트의 메모리가 필요하다고 가정해본다면 이 경우에는 300 바이트가 필요합니다. 즉 어플리케이션의 전체 15000 바이트 주소 공간을 사용하는 것보다 훨씬 적은 메모리 용량을 사용합니다. 따라서 만일 어플리케이션 실행시 필요한 메모리 요건을 기억할 수 있는 방법을 찾을 수가 있다면, 어플리케이션의 주소 공간 보다 적은 메모리를 사용하여 어플리케이션을 실행하는 것이 가능합니다.
어플리케이션의 나머지는 디스크에 남습니다.

ex.
필요한 페이지만 실제메모리에 올려두고
아닌 페이지는 디스크(스왑아웃)로 보내두고
페이지 테이블엔 invalid 표시해둔다.(디맨드 페이징이라서 그럼)
접근할 때, invalid라면 페이지 폴트 난 것이므로
IO작업(커널도움)으로 디스크에서 가져와야한다.
(이것이 바로 소프트웨어 인터럽트!)
IO작업은 굉장히 느리므로
페이지폴트가 나는 횟수가 성능 좌우.
즉,page 교체시 뭘 교체할건지 잘 골라야함.
(Optimal algorithm)
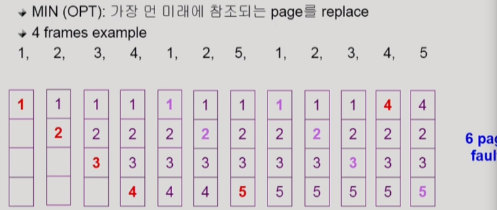
OPT: 가장 먼 미래에 어떤 페이지 참조하는지 알고 있다는 가정하에, 그 페이지를 교체
but 이건 알고 있어야되기 때문에 실제에선 미래보단 과거를 본다
FIFO: 가장 일찍 들어온 것을 가장 먼저 내보낸다.
but 프레임 커질수록 폴트 더 발생(왜?..혹시 갯수가 늘어나면 그만큼 확률도 떨어져서 그런가)
LRU(Least Recently Used):제일 오래전에 사용한거를 내쫒는다
->FIFO랑 다른 점은 먼저 들어왔어도 재사용 됐으면 안쫓아낸다는 사실이다//이 방법 젤 많이 쓴다
->링크드리스트로 처음 들어오면 밑에 달고, 뺼 때는 젤 위에꺼 뺸다.비교 필요 없다. O(1)
but 이번에 한번만 들어오고 앞으로 안들어올 애를 두고, 꾸준히 많이 들어오는 애를 보낼수도.
LFU(Least Frequntly Used): 가장 참조횟수가 적은 페이지 순으로 내쫓는다.
->O(n)...heap으로 구현해서 O(logn)에 가능.
but 이제 많아지려는애를 쫓아낼수도

밑에 정리 필요
캐슁환경;한정된 빠른공간에 요청된 데이터 저장해 뒀다가 후속요청시 캐쉬로부터 직접 서비스하는 방식
페이징의 TLB,캐쉬,버퍼,웹(얘는 단일시스템 아니고 다른 시스템에서 가져옴. 내 컴터에서 저장된걸로 보여줌)
swap)페이징의 캐쉽 적용 환경
file)캐쉬(cpu와 메인메모리 사이)의 적용환경
사실 lru,lfu는 버퍼랑 웹캐싱에만 쓰이지 페이징에는 안됨.
폴트 발생해서 새로 올라가면 접근시간 알 수 있어도 이미 있는 경우라면 참조만 해가기 때문에 정보 모름.
lru비슷하게 구현한 알고리즘이 클락 알고리즘임.
할당은 어떻게 잘 해두나? [사진]
ㄴ사실 lru.lfu같은 알고리즘 쓰면 알아서 조절되긴한다. (글로벌 리플레이스 활용)
<->로컬리플레이스(자신에게 할당된 프레임 내에서만 리플레이스..자기몫 나눠주고 알아서 바꿔써라)
+뭐가 더 좋을까?
폴트 너무 자주나면~~>Thrashing:
막는 알고?
워킹셋 알고리즘)

| 메모리 관리, 페이징, 세그멘테이션 (0) | 2019.10.26 |
|---|---|
| 데드락(Deadlock, 교착상태) (0) | 2019.10.18 |
| 프로세스 동기화 (0) | 2019.10.11 |
| 프로그램 생성과 종료,cpu 스케줄링 (0) | 2019.10.04 |
| 프로세스와 스케줄러, 스레드 (0) | 2019.09.30 |
컴퓨터에는 여러가지 메모리가 있다. 먼저 요약해서 그 관계를 얘기하자면, Disk(보조기억장치)에서 실행파일을 가상메모리에 올리고 페이지로 나눈다. 탐색시 보조디스크가 아닌 논리메모리만 탐색해서 필요한 페이지를 물리메모리에 적재시키고, 페이지테이블을 사용해서 그 순서를 기억한다.
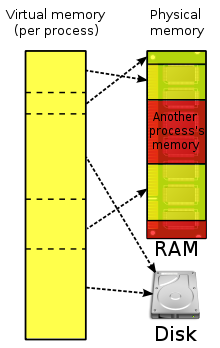
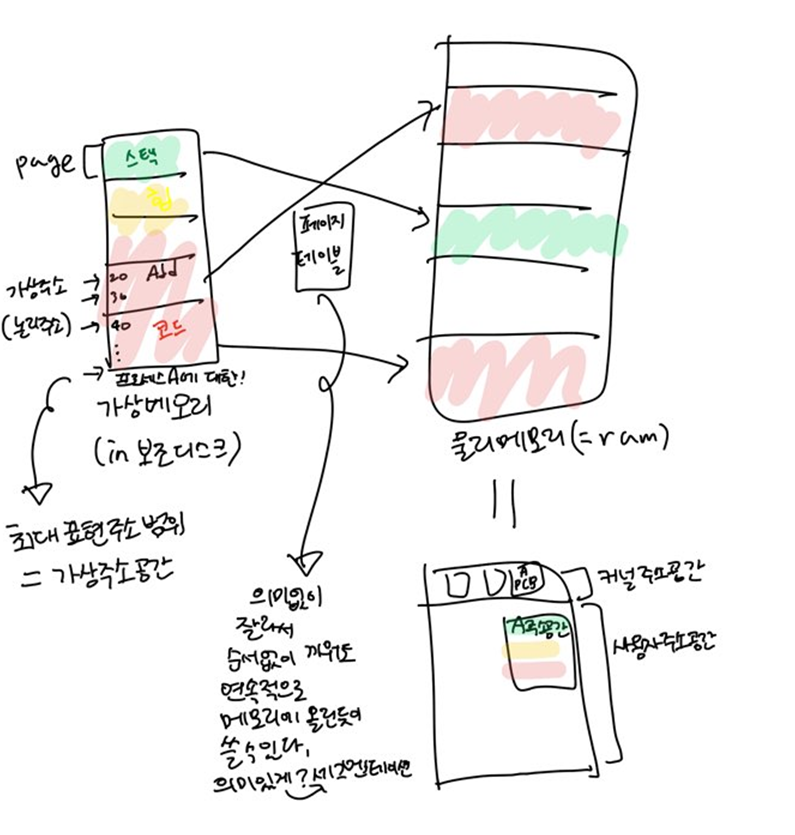
1.물리주소:주기억장치의 실제 저장위치 주소
2.가상메모리:보조기억장치를 주기억장치처럼 주소지정 가능하게 만든 저장공간 방법.
3.논리주소(가상주소):가상 메모리의 특정 위치에 배정된 주소 .각 프로세스 가상주소공간에서 0번지부터 시작. cpu가 보는 주소
4.가상주소공간:특정 프로세스에게 할당된 가상 주소의 영역
5.주소공간:특정 프로세스가 접근할 수 있는 메모리 주소의 영역
3.심볼릭 주소: 프로그래머 편의를 위한 변수
심볼릭 주소->컴파일->논리주소->주소바인딩->물리주소 과정을 거쳐서 메모리에 접근할 수 있다.
논리주소를 물리주소로 변환하는 바인딩 종류는 세 가지가 있다.

컴파일타임바인딩:
논리주소에서 정한 주소를 물리주소에서 그대로 사용하기 때문에, 프로그램 쓰면 빈공간을 찾아서 쓰지 않으므로 비효율적이다.
로드타임바인딩:
롸?//논리주소에서 계산해서 사용
런타임바인딩:
cpu를 뺏겨 메모리에서 나갔다가 들어올때 마다 주소가 바뀐다.(하드웨어 mmu가 지원이 필요하고 현대에 채택함)
cpu는 논리주소를 사용한다. 즉, cpu가 준 논리주소를 mmu가 물리주소로 변환을 해서 메모리에 접근하는 것이다. 이 과정을 바인딩이라고 한다.
cpu가 논리주소만 볼 수 밖에 없는 이유??
컴파일을 하고나서 실행파일을 cpu가 읽는데, 파일한 환경과 파일을 실행할 환경이 다른 경우, 실제 메모리값을 미리 알 수 없으므로 당연히 논리주소를 사용하여야 한다.
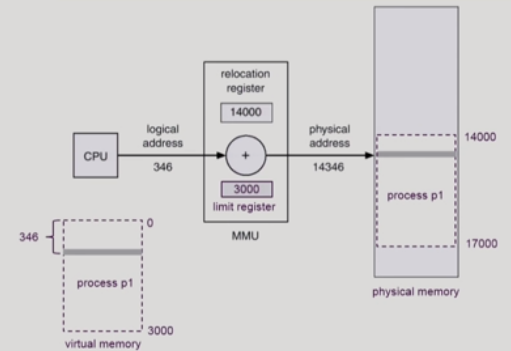
mmu는 하드웨어 장치로서,
접근하는 메모리 실제 주소=
가상주소공간의 0번쨰 논리주소에 해당하는 물리주소+cpu가 준 논리주소.
이때, 지정된 범위 벗어나는지 검사하는 소프트웨어 인터럽트가 존재한다.
주메모리에 접근해서 프로세스 주소공간이 배치된다.

-연속배치(각 프로세스가 메모리에 연속적으로 배치)
-불연속배치(하나의 프로세스가 메모리에 나눠져서 배치 됨,현대):페이징,세그멘테이션
-고정분할(사용자메모리 영역을 미리 파티션으로 나눠둠 ):페이징
-가변분할(미리 나눠두지 않고 들어오는대로 받아들임):세그멘테이션
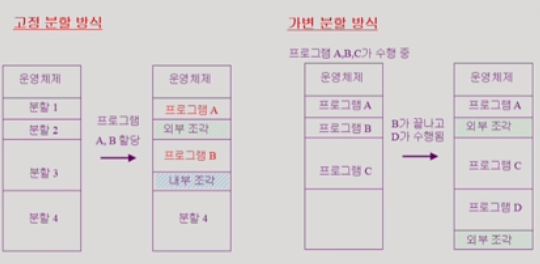
| 고정분할방식 | 가변분할방식 |
| 같은 크기든 다른 크기든 메모리를 미리 파티션으로 나눠둠 | 미리 나눠두지 않고 들어오는대로 배치한다 |
| 크기가 맞는 것이 나올때까지 건너뛰므로 외부단편화 발생 | 먼저 수행을 마친 프로세스가 나가서 중간에 외부단편화 발생 |
| 할당된 공간에 비해 필요한 공간이 작으면 내부단편화 발생 | 처음부터 필요한만큼 크기 할당받으므로 내부단편화는 없다 |
단편화 해결방법:(바인딩을 많이 해야되서 비용이 많이 들고 주소가 계속 바뀌므로 런타임바인딩이 지원되야 함)
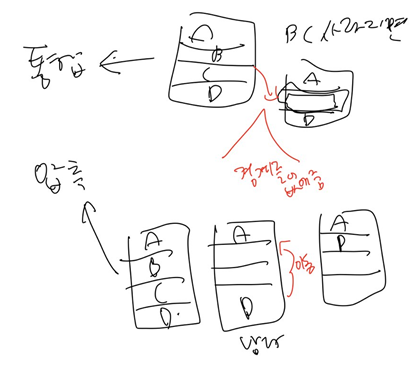
배치전략
1.first fit:사이즈가 n이상인 것중 처음 발견되는 것
2.best fit:가장 갭이 작은 홀로
3.worst fit: 가장 큰 홀로(장기적으로 안좋다..더 큰 프로세스 왔을때 써야하는데..)
스와핑: 메모리에서 cpu우선순위 낮은 프로세스를 디스크로 쫓아내거나 불러오는 것.(중기스케줄러)
롸?//동적로딩(동적:필요할 때마다 쓴다 ,로딩: 메모리에 올리는 것):
개발자가 방어적인 코드(예외처리코드)처럼 자주 쓰지 않는 코드를 명시적으로 나타내서 필요할 때만 부름.
+어떤거?
동적링킹(링킹:내가 사용하는 라이브러리 등의 코드를 실행할 때 코드로 붙여주는 것 동적:필요할 때마다):
static linking-컴파일하면 내 코드에 그 코드들이 추가가 된다.
dynamic linking-파일로 라이브러리에 코드있고 그 주소로 가는 거만 저장해둬서 필요할 때 그 동작만 수행
ㄴ이래서 printf함수 입출력 함수 쓰면 오래 걸린다는거구나..
오버레이:
What?
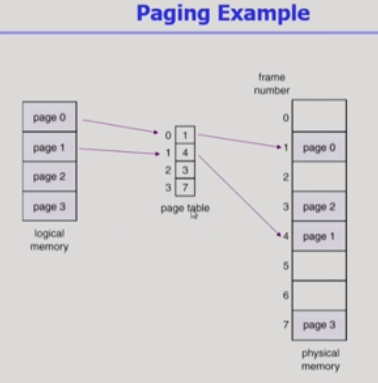
주메모리에서 사용하기 위해 2차 기억 장치로부터 데이터를 저장하고 검색하는 메모리 관리 기법이다.
How?
가상메모리를 모두 같은 크기의 페이지로 나누고 페이지는 같은 크기로 주메모리로부터 프레임을 할당받아서 적재된다.
인덱스로 바로 접근할 수 있는 페이지 테이블을 가지고 있다.
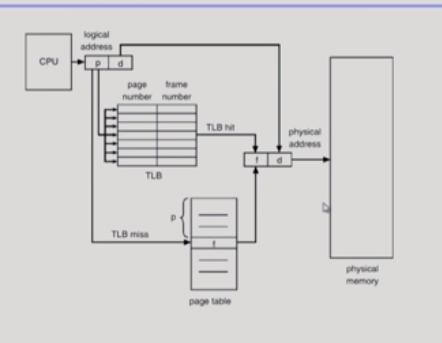
페이지 주소와 offset으로 이루어진 키값 테이블.
p,d => p페이지 d번째라는 뜻
(페이지 테이블에서 p에 해당하는 물리주소 f를 찾아서 d만큼 떨어진 실제주소를 찾는다.)
Where?
캐시에 넣기엔 너무 크고,에 넣기엔 빠르게 주소변환 해야하는데 부적절해서 메모리에 넣는다...
즉,
주메모리에 2번 접근한다<-속도 높이기 위해서 TLB(캐시역할하는 테이블,메인메모리와 cpu사이 하드웨어로 존재) 쓴다.
32bit에선 주소를 2^32까지 표현할 수 있다. 2^30은G이므로 4G.
이때, 주소 하나당 한 페이지인데 한 페이지는 최대 4K이므로
프로그램은 최대 4G/4K=100만개의 페이지로 구성되어 있다.
페이지테이블의 엔트리가 4바이트이므로 프로세스마다 4메가의 페이지테이블이 필요하게 되어 메모리 공간이 낭비된다.
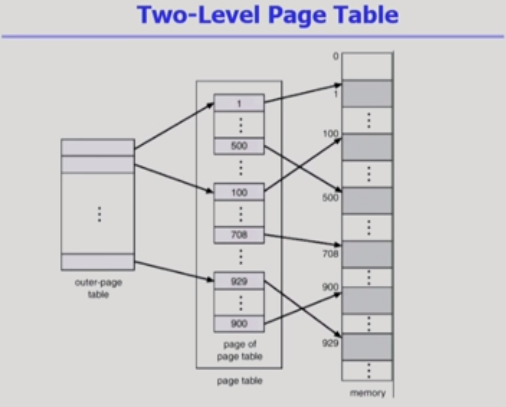
2단계 페이지 테이블!
속도는 줄어들지 않아도
공간은 줄어든다.
->비효율->2단계로 가자~~
->근데 2단계 페이지테이블까진 몬하게따 힘들다
프로세스가 공유하는 코드 있으면 메모리에 하나만 올림.
(shared code=pure code)<-read only여야함. ipc통신의 쉐어드 메모리랑은 다른 것
What?
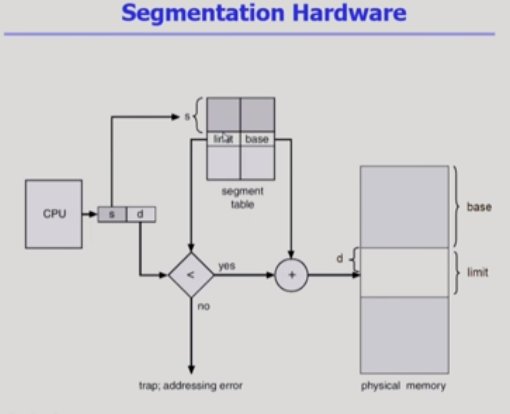
주메모리에서 사용하기 위해 2차 기억 장치로부터 데이터를 저장하고 검색하는 메모리 관리 기법이다.
How?
가상메모리를 의미적인 세그먼트로 나눈다.
(sharing하거나protection)
페이징은 크기 고정되어있지만 세그먼트는 가변적이므로 프로세스 초기위치 말고도 limit이 필요하다.limit 연산 시 할당크기 넘는다하면
할당 안함.
| 페이징 | 세그멘테이션 |
|
엔트리에 권한값을 부여해 페이지마다 read only/write등을 달아줘야한다. |
의미단위라 그런 문제는 없고 |
| allocation문제가 발생하지 않는다. | allocation문제가 발생할 수 있다. |
| 테이블에 의한 메모리 낭비는 페이징이 더 크다. | |
| 페이징은 갯수 알 수 있는데 | 갯수 추측 못함. |
|
내부단편화 있고(페이지보다 작으면 무조건 발생) 외부단편화는 불연속이라서 없다 |
내부단편화는 없지만 외부단편화는 있다 |
+새그맨트~페이지 섞어서 쓰기도..
+프로세스의 메모리 접근시 cpu가 바로 접근 가능. but IO장치 접근할때만 커널도움 받음.
| 가상메모리(Virtual Memory),페이지 교체 알고리즘 (2) | 2019.10.31 |
|---|---|
| 데드락(Deadlock, 교착상태) (0) | 2019.10.18 |
| 프로세스 동기화 (0) | 2019.10.11 |
| 프로그램 생성과 종료,cpu 스케줄링 (0) | 2019.10.04 |
| 프로세스와 스케줄러, 스레드 (0) | 2019.09.30 |
여러 프로세스가 같은 자원을 기다리며 blocked된 상태.
롸?//지금 충분하게 있는 자원상태 혹은 자원이랑 뱉어낼 애 있는 상태 합,...<-이 시퀀스가 되면 safe하다고 함.
상호배제(Mutual exclusion) : 한번에 여러 프로세스가 쓸 수 없는 자원이다
2.점유대기 : 자원을 사용중인 프로세스가 자원을 내놓지 않는다
3.비선점 : 다른 프로세스로부터 자원을 빼앗을 수 없다
4.순환대기 : 프로세스가 순환적으로 자원을 요구한다. 1번 자원을 사용하며 2번 자원을 기다리고, 2번 자원을 사용하며 3번 자원을 기다리고, 3번 자원을 사용하며 1번 자원을 기다리는 세 개의 프로세스.
예방-> 데드락 성립조건 4가지중 하나라도 충족되지 않도록 만든다.
1.상호배제-> 상호배제 조건을 제거한다
2.보유대기->한 프로세스에게 가용 자원을 모두 할당시키고 결국 스스로 내놓게 만듬
Issue->일어나지도 않은 일을 위해 자원들 몰아서 써서 성능이 낮아진다.
3.비선점-> 선점 가능한 프로토콜을 만든다. (ex. 프로세스가 cpu 선점 시 상태를 저장해둠)
4.순환대기->사이클이 없도록 순서를 정한다.(ex.1번을 획득해야만 2번획득)
회피-> 미리 사용할 자원을 모두 정의해둔 것을 바탕으로 데드락을 발생시킬 가능성이 높은 프로세스에게는 자원 할당을 안해준다.
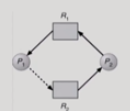
실선은 자원을 사용중이라는 뜻, 점선은 언젠가 한번은 쓸 자원이라는 뜻일 때,
점선이 향하는 자원을 p1에게 주면 사이클이 생겨서 데드락이 발생할 것을 알고 자원을 할당해주지 않는다.
or
가용자원에서 최대를 쓸 수 있는 프로세스에게'만' 자원을 줘서 보유대기예방과 같은 효과를 낸다.(은행원 알고리즘)
발견->
1)자원할당그래프를 그려서 사이클을 찾아본다
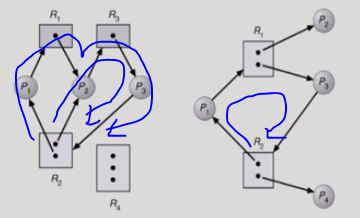
그래프에 사이클이 있으면 데드락'일 수도 있다.'
(인스턴스가 하나면 무조건 데드락인데 인스턴스가 두개면..)
왼쪽: 데드락이다.
오른쪽: 데드락 아니다. 사이클이 있긴하지만 P4가 여분을 쓰다가 반납하면 쓸 수 있는 상황이기 때문이다.
다양한 그래프 종류가 있다..
롸?// 사이클 찾는 시간복잡도? n^2! 간선 다 따라가보면 된느데
간선이 결국 하나에서 모든 곳에 다 뻗쳐도 n-1개기 때문.
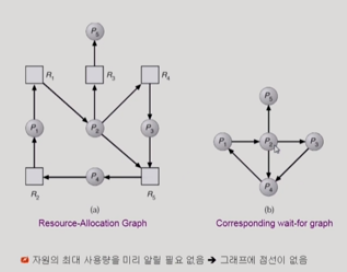
2)자원할당테이블을 그려서 가용자원들 쌓아서 생각해보고 시퀀스가 가능한지 합쳐나가면서 체크한다.(추천)

a 7,b 2,c 6개가 있는데 allocation처럼 프로세스들에게 분할이 되어있는 상태이다.
이 상태에서 p1,p2,p3,p4가 request와 같이 자원을 추가 요청한다.
이때, 가용자원은 없지만 낙관적으로 생각해서, p0같은 경우 반납할거라고 생각한다. 그럼 요청을 받아들이는 시퀀스가 존재하므로 다 만족할 수 있어서 데드락이 아니다 .

하지만 p2가 자원 c를 더 요청한다면 ,
요청한 자원도 만족할 때까지 본인이 가진 자원을 내놓지 않기 때문에 시퀀스가 불가능하고, 데드락이다.
*데드락은 최대한 낙관적이게 생각해도 데드락인 경우에만 데드락이라 판정한다*
회복->
1.모두 죽인다.
2.차례로 하나씩 죽여본다.
3.특정 기준으로 하나만 지목하여 죽인다.(Issue:꼭 자원이 적은걸로만 하면 기아현상 될수도..)
4.회복 안하고 무시한다.( 데드락 판별 알고리즘을 코드로 넣는 것 등은 성능을 저하시키므로, 차라리 인간이 직접 처리하는 것이 낫기 때문에 요즘 채택하는 방식이다.)
| 가상메모리(Virtual Memory),페이지 교체 알고리즘 (2) | 2019.10.31 |
|---|---|
| 메모리 관리, 페이징, 세그멘테이션 (0) | 2019.10.26 |
| 프로세스 동기화 (0) | 2019.10.11 |
| 프로그램 생성과 종료,cpu 스케줄링 (0) | 2019.10.04 |
| 프로세스와 스케줄러, 스레드 (0) | 2019.09.30 |