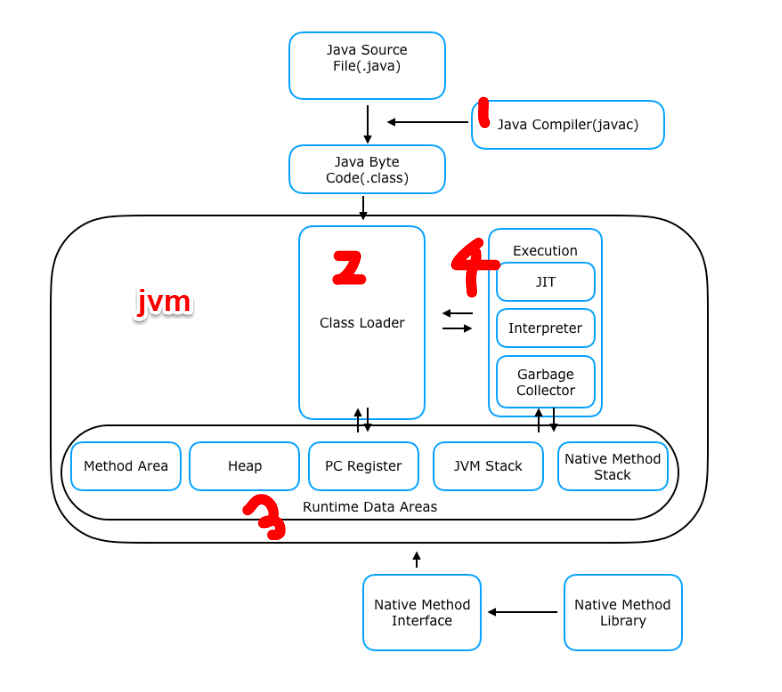
what?
applicationContext.xml에서 base-package 값을 다른 패키지 경로로 지정해주면 스프링 빈 등록과 코드실행도 잘 되는데 다른 패키지로 하면 404 에러가 떴다. 콘솔에는 경고만 뜨고 심각은 뜨지 않았다.
how?
아래는 성공 전까지 시도했던 방법들이다.
1.톰캣 재시작(처음 톰캣 실행이 안되는 에러를 잡을 수 있었다. 하지만 404에러는 잡히지 않았다)
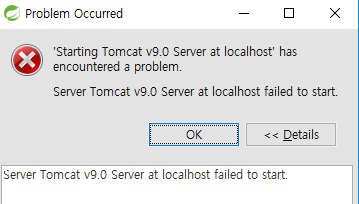
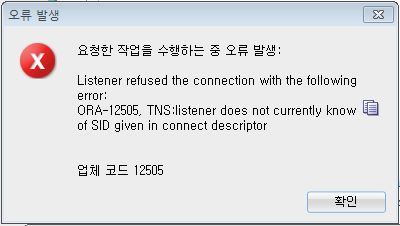
error:
Server Tomcat v7.0 Server at localhost failed to start
Servers->톰캣 우클릭->Delete->새 톰캣 서버 만들기
2.maven update
프로젝트 우클릭->Maven->Update Project
3.각종 버전 수정
xml파일에 java version 관련된 값들이 올바르게 설정되어있는지 확인
4.오타확인(""값으로 들어가면 컴파일 에러도 안뜨니 주의하자)
실행되는 자바파일의 AbstractApplicationContext를 생성하는 부분에 "applicationContext" 값의 't'를 뺴먹었었다.
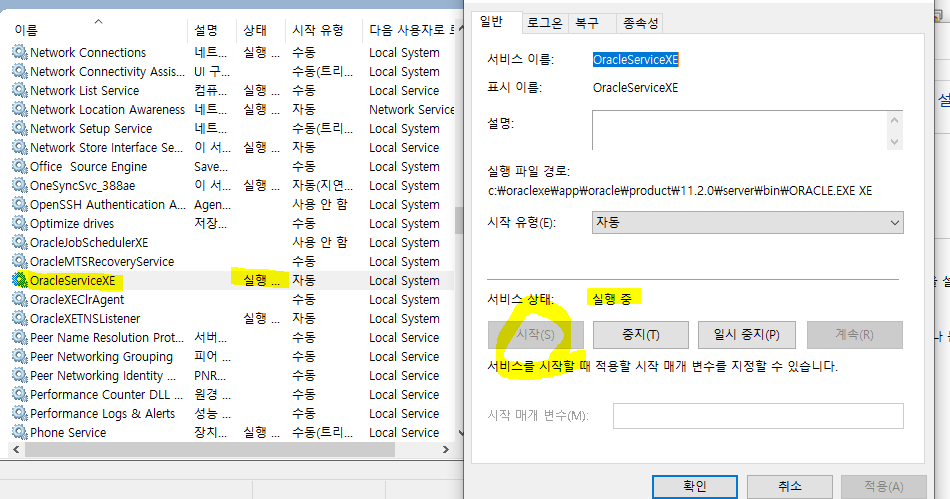
5.서버 옵션 체크
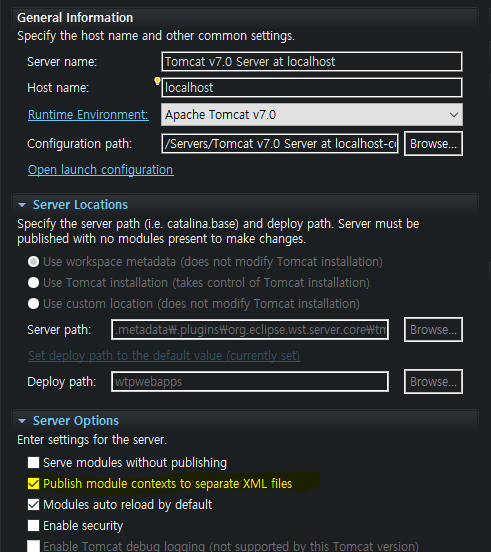
error:
setting property 'source' to 'org.eclipse.jst.jee.server:boardweb' did not find a matching property.
Servers->톰캣 더블클릭->overview의 sever options에서 'public module contexts to separate XML files' 체크.
6.run 세팅 확인(성공한 방법)
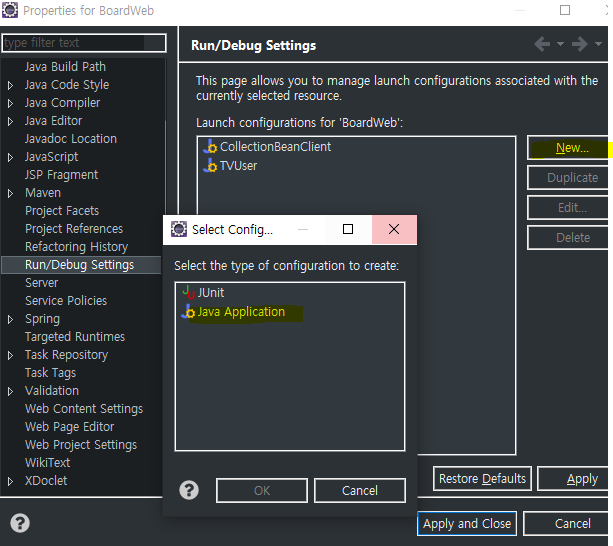
알고보니 내가 실행하려는 BoardServiceClient가 프로젝트 실행 소스로 등록이 되어있지 않았다! 그래서 추가해주고 돌리면 에러가 나지 않는다. 등잔 밑이 어둡다..
프로젝트 우클릭->properties->run/debug->new->시작할 소스 추가
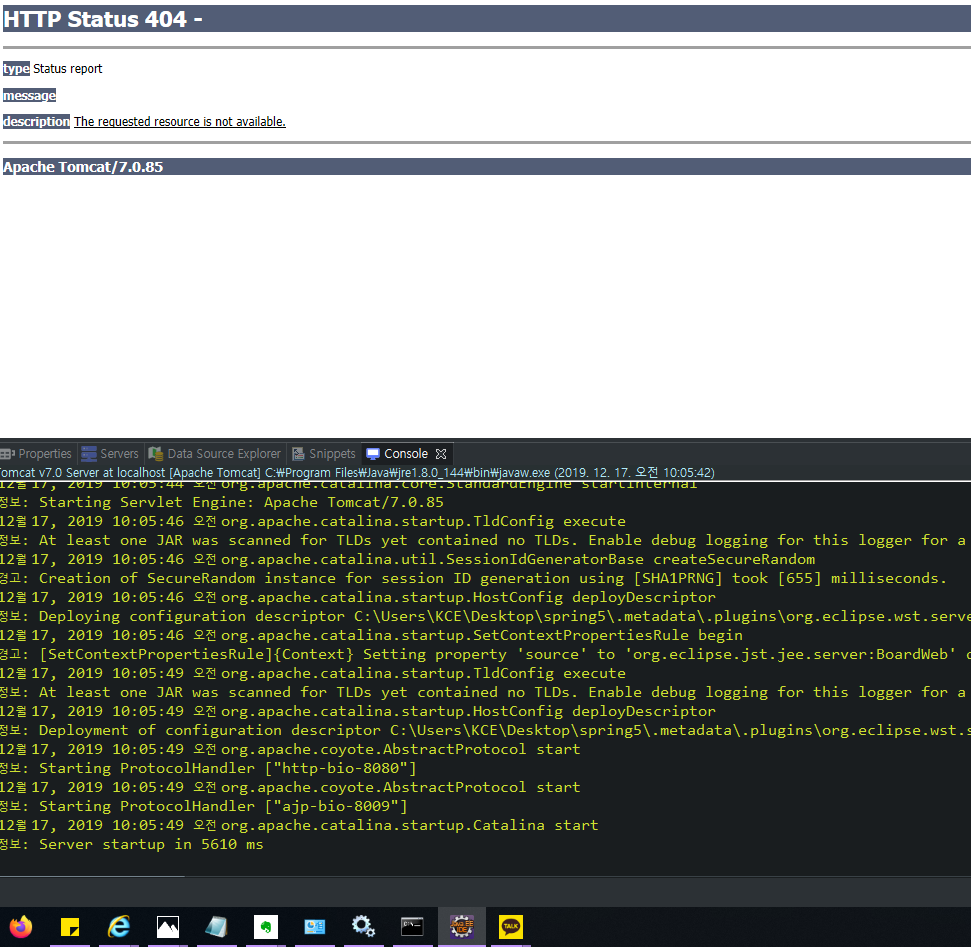
아래는 콘솔창 로그이다.
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: Server version: Apache Tomcat/7.0.85
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: Server built: Feb 7 2018 18:52:33 UTC
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: Server number: 7.0.85.0
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: OS Name: Windows 10
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: OS Version: 10.0
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: Architecture: amd64
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: Java Home: C:\Program Files\Java\jre1.8.0_144
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: JVM Version: 1.8.0_144-b01
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: JVM Vendor: Oracle Corporation
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: CATALINA_BASE: C:\Users\KCE\Desktop\spring5\.metadata\.plugins\org.eclipse.wst.server.core\tmp0
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: CATALINA_HOME: C:\Program Files\apache-tomcat-7.0.85
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: Command line argument: -Dcatalina.base=C:\Users\KCE\Desktop\spring5\.metadata\.plugins\org.eclipse.wst.server.core\tmp0
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: Command line argument: -Dcatalina.home=C:\Program Files\apache-tomcat-7.0.85
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: Command line argument: -Dwtp.deploy=C:\Users\KCE\Desktop\spring5\.metadata\.plugins\org.eclipse.wst.server.core\tmp0\wtpwebapps
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: Command line argument: -Djava.endorsed.dirs=C:\Program Files\apache-tomcat-7.0.85\endorsed
12월 17, 2019 10:05:43 오전 org.apache.catalina.startup.VersionLoggerListener log
정보: Command line argument: -Dfile.encoding=MS949
12월 17, 2019 10:05:43 오전 org.apache.catalina.core.AprLifecycleListener lifecycleEvent
정보: The APR based Apache Tomcat Native library which allows optimal performance in production environments was not found on the java.library.path: C:\Program Files\Java\jre1.8.0_144\bin;C:\WINDOWS\Sun\Java\bin;C:\WINDOWS\system32;C:\WINDOWS;C:/Program Files/Java/jre1.8.0_144/bin/server;C:/Program Files/Java/jre1.8.0_144/bin;C:/Program Files/Java/jre1.8.0_144/lib/amd64;C:\oraclexe\app\oracle\product\11.2.0\server\bin;C:\ProgramData\Oracle\Java\javapath;C:\Program Files (x86)\Intel\iCLS Client\;C:\Program Files\Intel\iCLS Client\;C:\WINDOWS\system32;C:\WINDOWS;C:\WINDOWS\System32\Wbem;C:\WINDOWS\System32\WindowsPowerShell\v1.0\;C:\Program Files (x86)\Intel\Intel(R) Management Engine Components\DAL;C:\Program Files\Intel\Intel(R) Management Engine Components\DAL;C:\Program Files (x86)\Intel\Intel(R) Management Engine Components\IPT;C:\Program Files\Intel\Intel(R) Management Engine Components\IPT;C:\Program Files\Intel\WiFi\bin\;C:\Users\KCE\Documents\opencv\build\x64\vc14\bin;C:\Program Files\Java\jdk1.8.0_144bin;C:\Users\KCE\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Python 3.6;C:\WINDOWS\System32\OpenSSH\;C:\Program Files\Git\cmd;C:\Program Files\Common Files\Intel\WirelessCommon\;C:\Program Files\Android\Android Studio\jre\bin;C:\Program Files\PuTTY\;C:\Users\KCE\AppData\Local\Microsoft\WindowsApps;C:\Program Files\R\R-3.5.1\bin\x64;C:\Users\KCE\Documents\R\win-library\3.5\rJava\jri\x64;C:\Users\KCE\AppData\Local\Microsoft\WindowsApps;C:\devtool\apache-maven-3.6.2\bin;;C:\Users\KCE\Desktop;;.
12월 17, 2019 10:05:43 오전 org.apache.coyote.AbstractProtocol init
정보: Initializing ProtocolHandler ["http-bio-8080"]
12월 17, 2019 10:05:44 오전 org.apache.coyote.AbstractProtocol init
정보: Initializing ProtocolHandler ["ajp-bio-8009"]
12월 17, 2019 10:05:44 오전 org.apache.catalina.startup.Catalina load
정보: Initialization processed in 834 ms
12월 17, 2019 10:05:44 오전 org.apache.catalina.core.StandardService startInternal
정보: Starting service Catalina
12월 17, 2019 10:05:44 오전 org.apache.catalina.core.StandardEngine startInternal
정보: Starting Servlet Engine: Apache Tomcat/7.0.85
12월 17, 2019 10:05:46 오전 org.apache.catalina.startup.TldConfig execute
정보: At least one JAR was scanned for TLDs yet contained no TLDs. Enable debug logging for this logger for a complete list of JARs that were scanned but no TLDs were found in them. Skipping unneeded JARs during scanning can improve startup time and JSP compilation time.
12월 17, 2019 10:05:46 오전 org.apache.catalina.util.SessionIdGeneratorBase createSecureRandom
경고: Creation of SecureRandom instance for session ID generation using [SHA1PRNG] took [655] milliseconds.
12월 17, 2019 10:05:46 오전 org.apache.catalina.startup.HostConfig deployDescriptor
정보: Deploying configuration descriptor C:\Users\KCE\Desktop\spring5\.metadata\.plugins\org.eclipse.wst.server.core\tmp0\conf\Catalina\localhost\biz.xml
12월 17, 2019 10:05:46 오전 org.apache.catalina.startup.SetContextPropertiesRule begin
경고: [SetContextPropertiesRule]{Context} Setting property 'source' to 'org.eclipse.jst.jee.server:BoardWeb' did not find a matching property.
12월 17, 2019 10:05:49 오전 org.apache.catalina.startup.TldConfig execute
정보: At least one JAR was scanned for TLDs yet contained no TLDs. Enable debug logging for this logger for a complete list of JARs that were scanned but no TLDs were found in them. Skipping unneeded JARs during scanning can improve startup time and JSP compilation time.
12월 17, 2019 10:05:49 오전 org.apache.catalina.startup.HostConfig deployDescriptor
정보: Deployment of configuration descriptor C:\Users\KCE\Desktop\spring5\.metadata\.plugins\org.eclipse.wst.server.core\tmp0\conf\Catalina\localhost\biz.xml has finished in 2,626 ms
12월 17, 2019 10:05:49 오전 org.apache.coyote.AbstractProtocol start
정보: Starting ProtocolHandler ["http-bio-8080"]
12월 17, 2019 10:05:49 오전 org.apache.coyote.AbstractProtocol start
정보: Starting ProtocolHandler ["ajp-bio-8009"]
12월 17, 2019 10:05:49 오전 org.apache.catalina.startup.Catalina start
정보: Server startup in 5610 ms
+처음 404에러가 떴을때 콘솔에 뜬 로그를 봤을때, 자꾸 appServlet과 home.js가 찍혀나오는걸 보고 짠 적도 없는게 왜 나오지...? 싶었는데, spring legacy를 만들면 자동적으로 생성되는거라고 한다. 그래서 webapp 폴더를 삭제했다. 그러나 war로 패키징 되도록 설정되있어서 반드시 web.xml이 있어야만 했다(서블릿3.0버전부터는 없애기 가능)
https://minwan1.github.io/2017/10/08/2017-10-08-Spring-Container,Servlet-Container/
Wan Blog
WanBlog | 개발블로그
minwan1.github.io
IoC 백날 공부해도 스프링 동작원리를 모르면 에러 하나 잡기가 많이 힘든 것 같다. 위 글에 잘 정리되어있으니 참고하자!