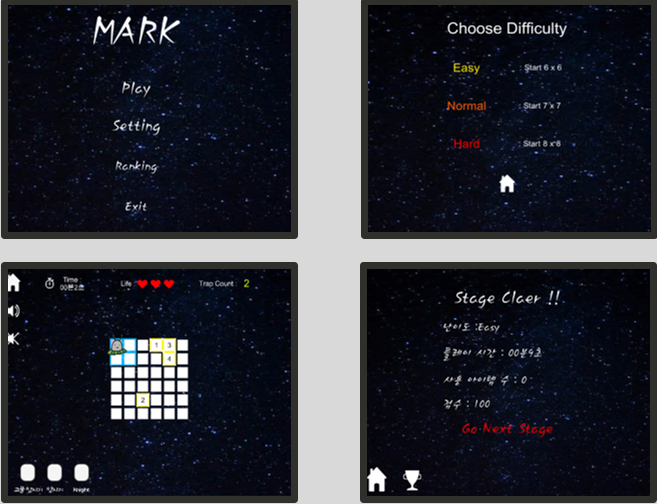
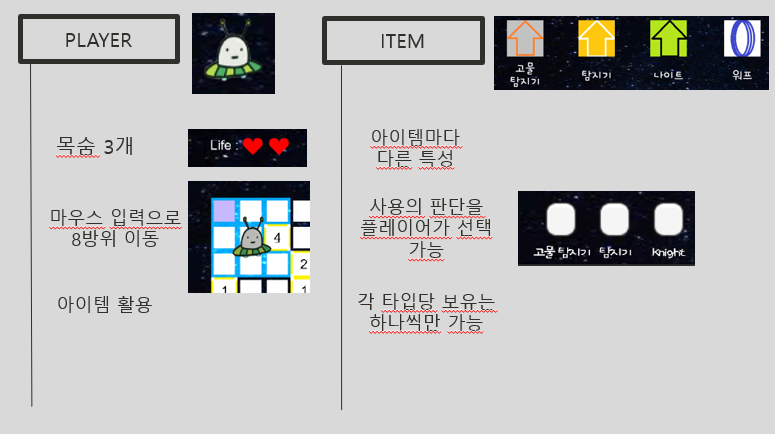
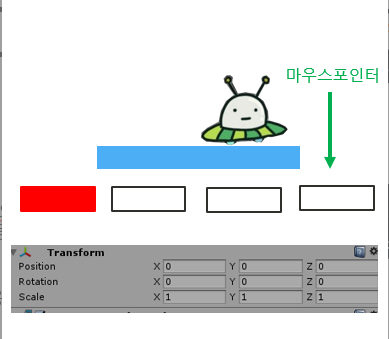
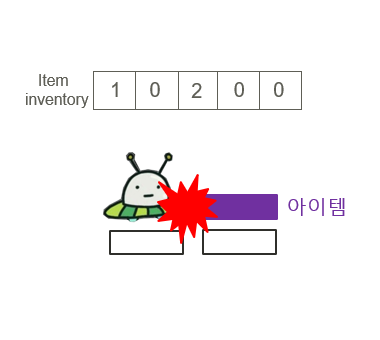
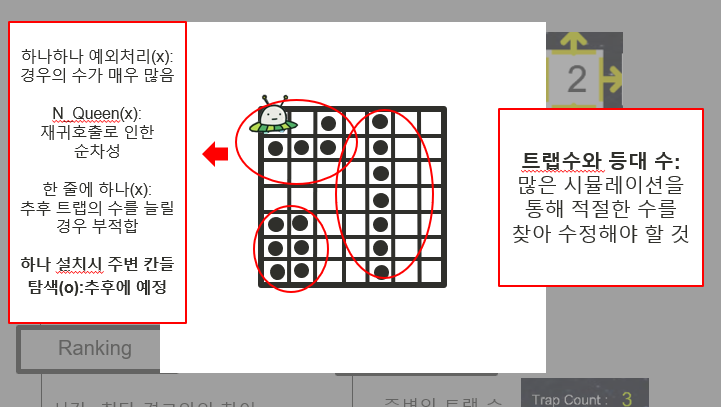
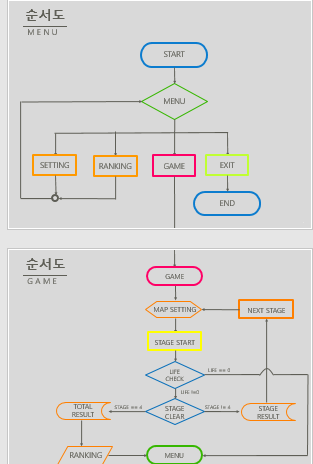
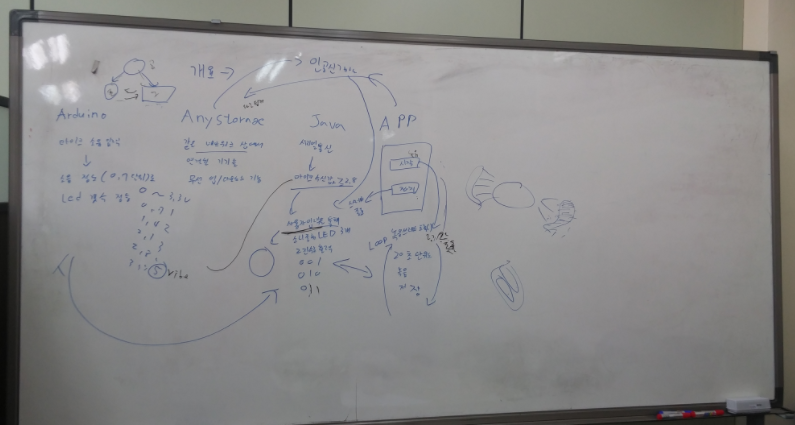
1)한줄요약 : 머신러닝을 활용한 위험소리알림,오픈소스 활용한 음성인식기능,SOS기능,보호자 등록 기능을 가진 안드로이드 앱을 제작
+비상알림벨: 경적,화재경보음,아기울음소리 등 위험소리를 감지하여 그 종류를 알려준다. 소리데이터 즉각적인 인지를 위해 진동을 발생시키고, 소리를 분석하여 화면에 이미지로 출력한다.
+소음측정기: 주변의 소음정도를 측정해 적절한 발화를 돕는다. 데시벨을 측정해 크기에 맞춰 LED를 점등시킨다.
+원터치 신고: 사회적 약자인 장애인을 겨냥한 범죄를 즉각 대처할 수 있도록 돕는다. 버튼을 특정 패턴으로 누르면 작동되어, 실시간으로 사용자의 위치와 녹음 파일을 서버로 전송한다.
+음성인식: 원활한 대화를 위해 상대방의 음성을 인식하여 모니터에 텍스트로 출력한다.
2)본인 역할 : 위험소리알림기능을 전담함. mfcc로 wav파일 특징값을 추출하고 ,svm으로 모델에 학습시켜 샘플의 분류결과값을 지정. 자신의 역할을 끝낸 뒤 안드로에드에서 모듈들을 합치는 것을 도와줌.
+팀원:천재영(웹),박진청(데이터베이스),이은경(소음측정기,음성인식),박신혜(원터치신고,구글맵)
3)본인이 사용한 스킬 : JAVA,Machine Learning(MFCC+SVM)
+팀원스킬: Google Map Api, Naver Speech Api,Android,PHP,Mysql
4)힘들었던 점:
+머신러닝이 어렵고 낯설었던 점->기술 레퍼런스,구조도를 활용해 맥락을 파악하려고 노력하며 디버깅
+머신러닝 분류기 선택할 때 팀원들을 설득하던 것->분류기마다 특성을 정리해 SVM이 더 적합한 이유를 얘기
+추출기의 출력 포맷이 분류기의 입력 포맷과 달랐는데 추출기 내부 함수를 수정하기 어려웠음->다른 IDE에서 미니 전처리 프로그램을 따로 만듬. 추후에 내부 함수 또한 수정하는데 성공했음.
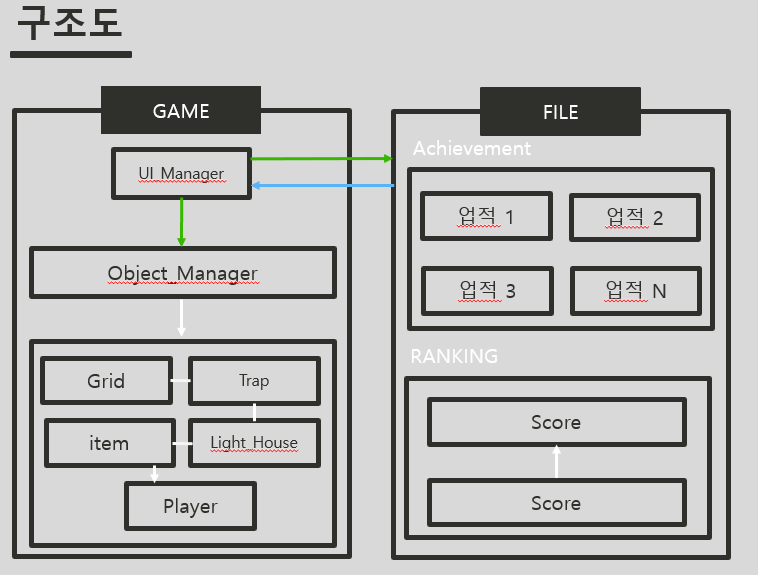
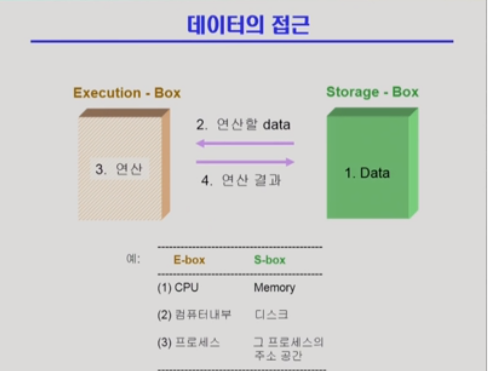
[전체구조도]
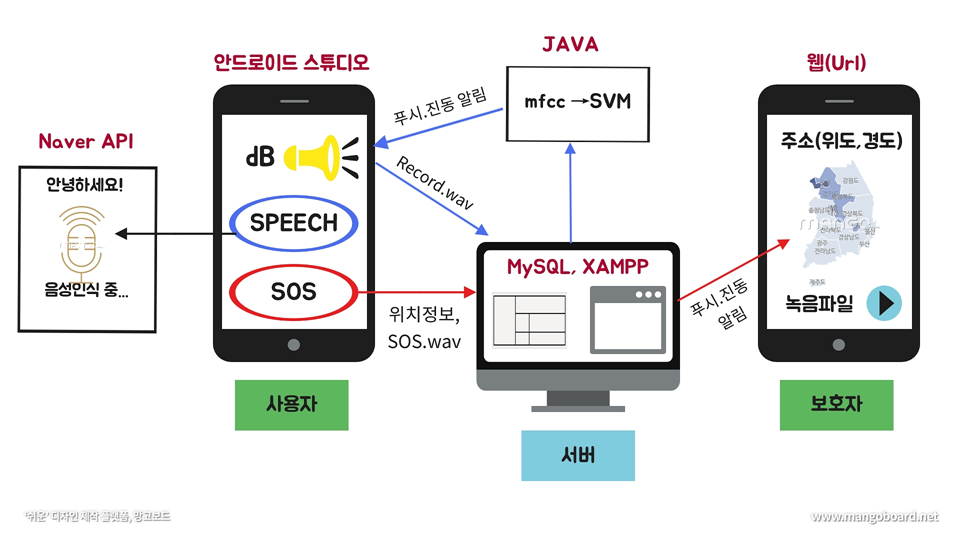
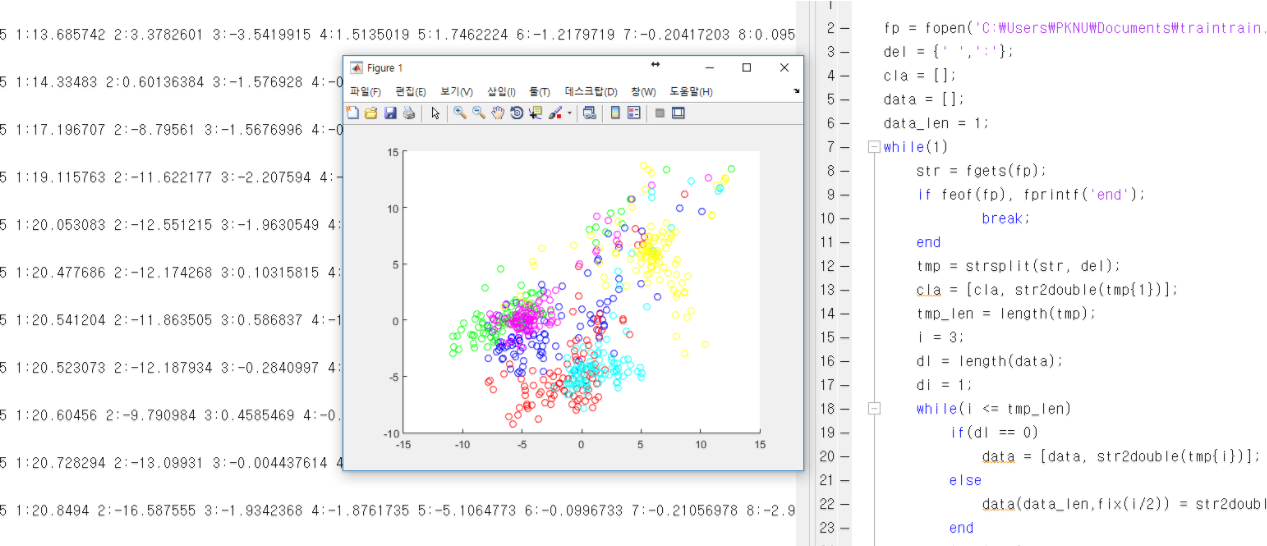
[미니전처리기를 통해 포맷팅을 한 결과]
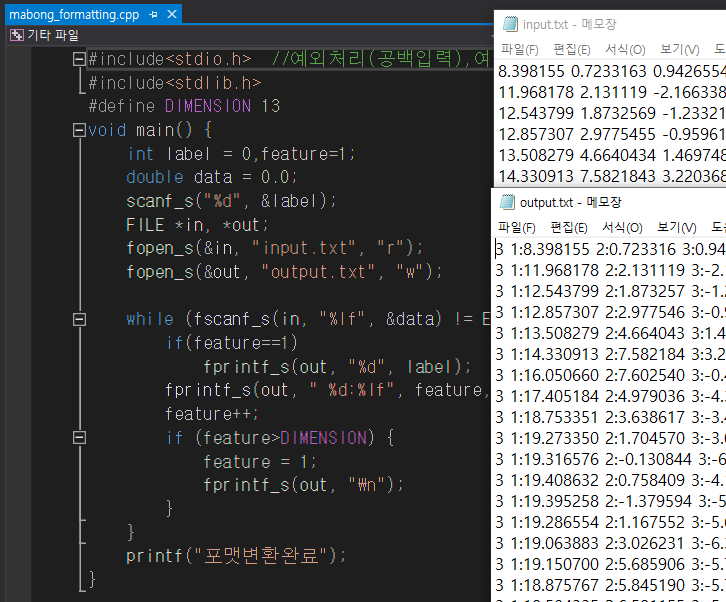
[제공되는 GUI를 활용하는 모습- 라이브러리는 livsvm 사용]
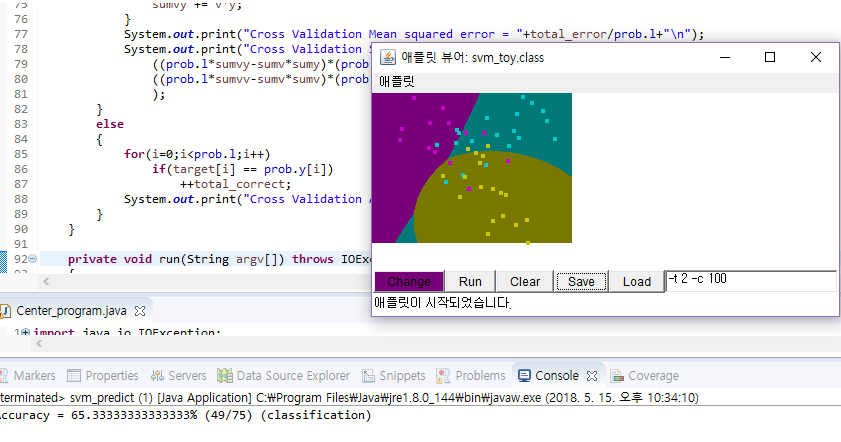
[실제 프로젝트 결과 모델의 분류 정도]
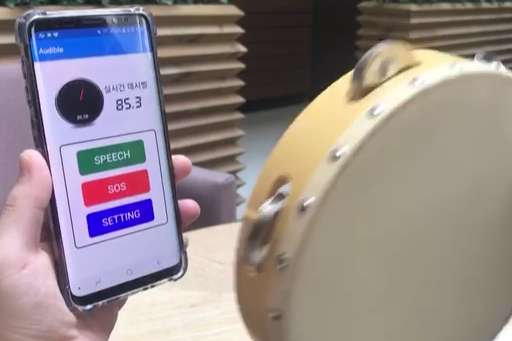
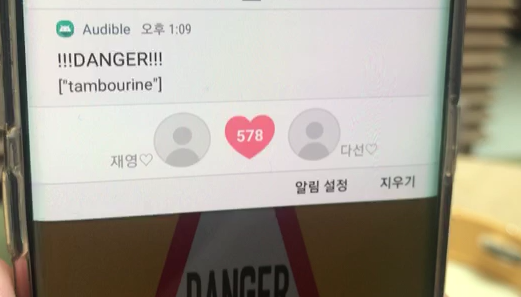
[실제 완성본 모습-데시벨 증가하는 모습, 분류해서 push 알림으로 도착한 모습, 보호자 로그인 기능..(다른 기능들은 사진이 없다)]

그 외의 자료들...
[주요 코드 1]
package edu.iitb.frontend.audio.feature;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Vector;
import javax.sound.sampled.AudioInputStream;
import javax.sound.sampled.AudioSystem;
import javax.sound.sampled.UnsupportedAudioFileException;
import edu.iitb.frontend.audio.util.AudioPreProcessor;
import edu.iitb.frontend.audio.util.MFCC;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
public class FeatureFileExtractor {
static float sampleRate = 8000;
public static int newWindowSize = 205;
public static int hopsize = 80;
static int numberCoefficients = 13;
static double minFreq = 133;
static double maxFreq = 3500;
static int numberFilters = 31;
/* 테스트 코드
public static void main(String argv[]) throws IOException, IllegalArgumentException, UnsupportedAudioFileException {
FeatureFileExtractor t = new FeatureFileExtractor();
t.computeFeatures("siren15", "/Users/KCE/Desktop/capstone/total_train_wav/siren", "/Users/KCE/Desktop/capstone/total_train_wav/siren");
}*/
static int label = 1; //분류값
public static void computeFeatures(String fileName, String inputFolder, String outputFolder) //문제의 포맷팅 처리 부분..기존에 visual stuio로 수정했지만 eclipse에서도 수정할 수 있게 됐다!
throws IllegalArgumentException, IOException, UnsupportedAudioFileException {
// WAV파일 읽음
String wavFile = inputFolder + "/" + fileName + ".wav";
System.out.println("converting " + wavFile + " to mfc");
File soundfile = new File(wavFile);
AudioInputStream audioIn = AudioSystem.getAudioInputStream(soundfile);
AudioPreProcessor in = new AudioPreProcessor(audioIn, sampleRate);
boolean useFirstCoefficient = true;
//MFCC처리
MFCC feat = new MFCC(sampleRate, windowSize, numberCoefficients, useFirstCoefficient, minFreq, maxFreq,
numberFilters);
Vector<double[]> features = feat.process(in, audioIn);
System.out.println("Vector Size :" + features.size());
// 포맷팅
BufferedWriter out = new BufferedWriter(new FileWriter("/Users/KCE/Desktop/capstone/not_trained_data/test.txt"));
try {
// create file output stream
double arr[];
for (int i = 0; i < features.size(); i++) {
arr = features.get(i);
if ((float) arr[0] < 30 && (float) arr[0] > -30) { // null
System.out.print(label + " "); // label
out.write(label + " "); // label
}
for (int j = 0; j < arr.length; j++) {
if ((float) arr[j] < 30 && (float) arr[j] > -30) { // null
System.out.print(j + 1 + ":" + (float) arr[j] + " ");
out.write(j + 1 + ":" + (float) arr[j] + " ");
if (j == arr.length - 1)
System.out.println();
//String numberAsString = new Float((float) arr[j]).toString(); // float -> string
//out.write(numberAsString + " ");
}
}
if ((float) arr[0] < 30 && (float) arr[0] > -30) // null
out.write("\n");
}
out.flush();
out.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
[주요 코드 2]
import java.io.IOException;
import javax.sound.sampled.UnsupportedAudioFileException;
import edu.iitb.frontend.audio.feature.FeatureFileExtractor;
public class test {
public static void main(String argv[]) throws IOException, IllegalArgumentException, UnsupportedAudioFileException
{
FeatureFileExtractor Feature = new FeatureFileExtractor();
Feature.computeFeatures("", // wavfile_name
"/Users/KCE/Desktop/capstone/total_train_wav/bark", // input_file_dir
"/Users/KCE/Desktop/capstone/bark"); // output_file_dir
svm_predict Predict = new svm_predict();
String dir[] = {"/Users/KCE/Desktop/capstone/not_trained_data/test.txt", // test_file(예측 시도해 볼 입력 파일)
"/Users/KCE/Desktop/capstone/model/traintrain.txt.model", // model_file(모델파일이 있는 경로)
"/Users/KCE/Desktop/capstone/model/traintrain.txt.out"}; // output_file(예측 결과가 저장되는 경로)
Predict.main(dir); //만들어진 모델로 예측
System.out.println(Predict.case_num);
if(Predict.case_num==1) //무슨 소리인지 분류 결과값 리턴
System.out.println("baby");
else if(Predict.case_num==2)
System.out.println("bark");
else if(Predict.case_num==3)
System.out.println("drill");
else if(Predict.case_num==4)
System.out.println("fire");
else if(Predict.case_num==5)
System.out.println("siren");
}
}
[프로젝트 진행사항 전달]
+참고자료: http://keunwoochoi.blogspot.kr/2016/01/blog-post.html : 다른 분류기를 사용하여 음악장르 분류 포스팅한 블로그
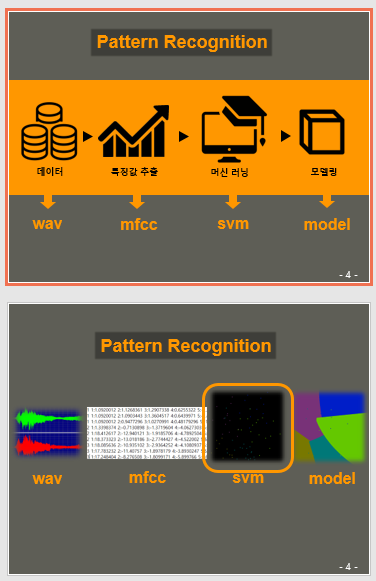
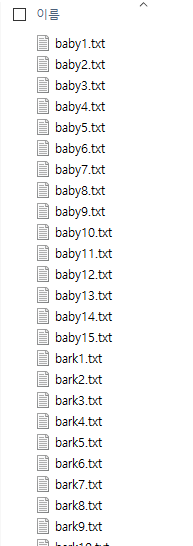
설명: 왼쪽부터 머신러닝 프로세스, 사용된 mfcc 파일,wav 파일이다.
원데이터는 분석을 위해 mp3아닌 wav파일 사용,프레임 길이 고려하여 5초 단위로 잘랐음. 축적된 데이터는 아기울음소리, 개짖는 소리, 사이렌소리,소방벨 소리 총 81개의 파일.
'Project' 카테고리의 다른 글
| [툰츄] (0) | 2019.11.06 |
|---|---|
| [부귀영화-영화 추천 서비스] (0) | 2019.10.25 |
| [WaterMelon-음원 사이트] (0) | 2019.10.25 |
| [MARK- 길건너기 2D 게임] (0) | 2019.10.25 |
| [hearable watch-청각장애인용 스마트 워치] (0) | 2019.10.25 |