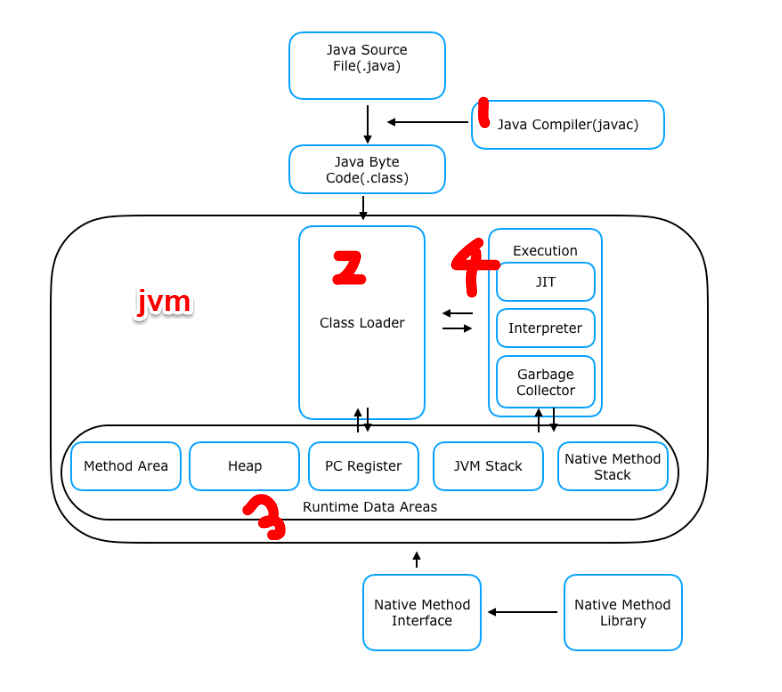
참고자료)이화여대 반효경 선생님 KOCW 강의
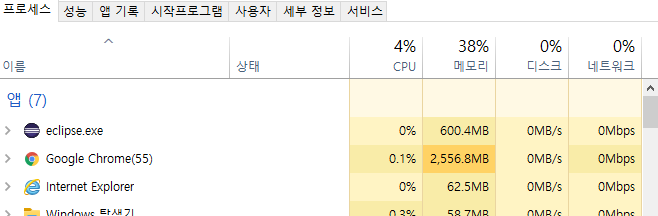
프로세스: 실행중인 프로그램이다.(윈도우 작업관리자 열면 볼 수 있는 것들!)
우리가 C하드(보조기억장치-하드,시디)에 저장하듯 하드디스크에 저장되어 있고,
그걸 실행하는 작업대가 ram(주기억장치-램,롬)이다. 컴퓨터의 메모리라고 하면 일반적으로 램을 말한다.
바로 프로그램이 램에서 작업이 되는건 아니고 커널에 의해 레디큐로 갈지 말지 결정해서 레디큐로 갔다가,(이 과정은 커널의 데이터영역에서 이루어진다.그리고 이 커널의 주소공간 또한 램에 있다! https://whereisusb.tistory.com/10 참고, 헷갈렸던거 제대로 나와있음) 디스패쳐를 통해 램에 올라가 cpu에게 처리받는다.
운영체제가 여러 프로그램을 실행하기 위해 자원(cpu,메모리,네트워크)을 분배한다.
How??일단 기준보다 방법을 먼저 보자!
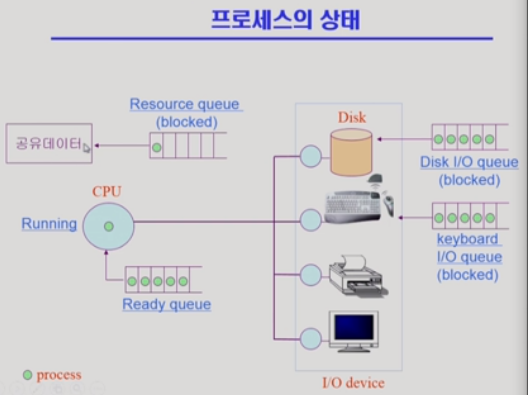
초록점이 프로세스 하나다.
CPU가 빠른 속도로 프로세스를 처리하고 있을 때 (해당프로세스상태:running)
정해진 시간이 끝나면(라운드로빈!) 큐의 뒤로 빠지고(해당프로세스상태:ready) 큐의 앞에 있던 프로세스가 시작된다.
혹은, 실행중인 프로세스가 IO처리가 필요하면 블록큐로 넘어가 끝날때까지 대기하게 된다.(해당프로세스상태:blocked)
IO에서 완료되면 cpu에 IO인터럽트를 해서 끝났다고 알려주고 CPU는 커널(깜빡깜빡!)을 통해 운영체제에게 아까 프로세스의 상태를 ready으로 바꿔달라고 요청한다. 우선적으로 처리할 수 있도록!
+프로세스의 상태(프로세스 스케줄링)
-running: CPU를 잡고 instruction을 수행중인 상태
-ready: (물리적으로 코드가 메모리에 올려져있는 둥 모든 조건 만족하고)CPU를 기다리는 상태
-blocked: CPU를 주어도 당장 instruction을 수행할 수 없는 상태(디스크에서 file을 읽어와야하는 경우)
ex) 어떤 프로그램이 사용자 입력을 읽고 처리하는 내용이면 키보드 입력 받기위해 프로세스를 키보드큐에 보내주고, 블락처리한다. 그동안 다른걸 수행하다가 키보드에 있던 애가 끝나면 키보드 컨트롤러가 cpu에게 인터럽트를 걸어서 알리고,cpu는 운영체제에게 프로세스상태를 ready로 바꾸도록해서 자신이 곧 실행할 수 있게 한다.
+공유데이터(면접질문!): IO 디바이스 서비스 기다리느라 block되는 경우 말고 소프트웨어 서비스 기다리느라 block되는 경우도 있다.
ex) 한 프로세스가 접근하는 도중에 cpu를 뺏겨서 다른 프로세스가 접근하면 일관성이 깨지므로 데이터를 막아둔 경우.
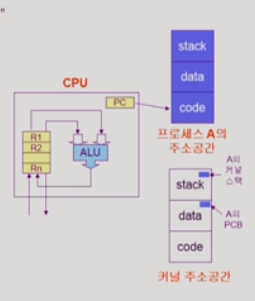
프로세스 실행) code가 stack에 쌓인다. 그 과정에서 data를 참조한다.
+JRE로 따지면 code,data영역이 코드와 static저장하는 method 영역 역할이고
stack은 jvm stack 역할이고 나와있진 않지만 heap은 그대로 heap역할을 하는듯하다.
인터럽트 등의 이유로 다른 프로세스로 문맥교환) 커널에게 요청(시스템콜)을 한다. pc의 주소는 프로세스주소공간이 아닌 커널 주소공간을 가리키게 된다.
운영체제-커널 동작) 프로세스 실행과정과 마찬가지이다. 다만, 커널은 자신의 data영역에 큐 자료구조를 만들어서 프로세스 상태를 변화시키며 순서를 바꾼다.
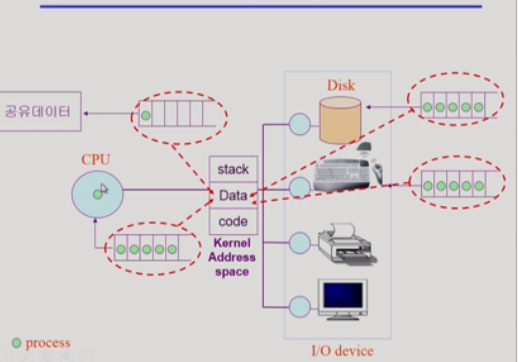
이때!!! 커널은 모든 프로세스가 접근할 수 있기 때문에 동시에 접근하는 경우를 막기 위해서
커널스택을 프로세스가 나눠가진다.
+그리고 위의 큐들이 모두 커널의 주소공간-데이터 영역에 있기 때문에
운영체제가 프로세스 스케줄링이 가능한 것
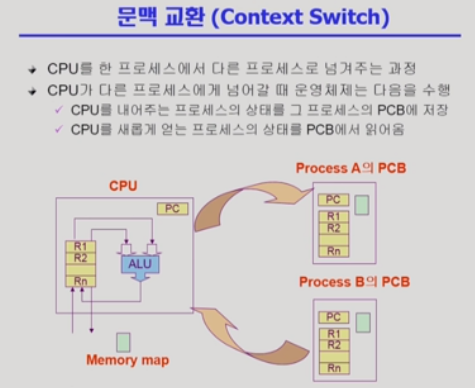
프로세스가 cpu를 뺏겼다가 다시 cpu를 되찾을 때 처음부터 다시 하는게 아니라 하던 곳에서 하려면 그 문맥 (레지스터 상황,코드 위치)을 기억해둬야 한다. 즉, cpu를 뺏기기 전에 해당 프로세스의 정보들을 자신의 PCB에 저장을 해두고 나중에 되찾을 때 cpu하드웨어에 그때의 상황을 복구를 하는 작업을 운영체제가 해준다.
+반드시 인터럽트나 시스템콜이 발생한다고 context switch가 발생하는건 아니다. 예를 들어서, 프로세스 A->인터럽트 발생(프로세스A를 위한)->프로세스A 의 상황이라면 프로세스가 바뀌는게 아니기 때문에 context switch가 발생하지 않는다. 문맥교환은 프로세스가 바뀔때 정보를 저장하는게 목적임을 명심하자!

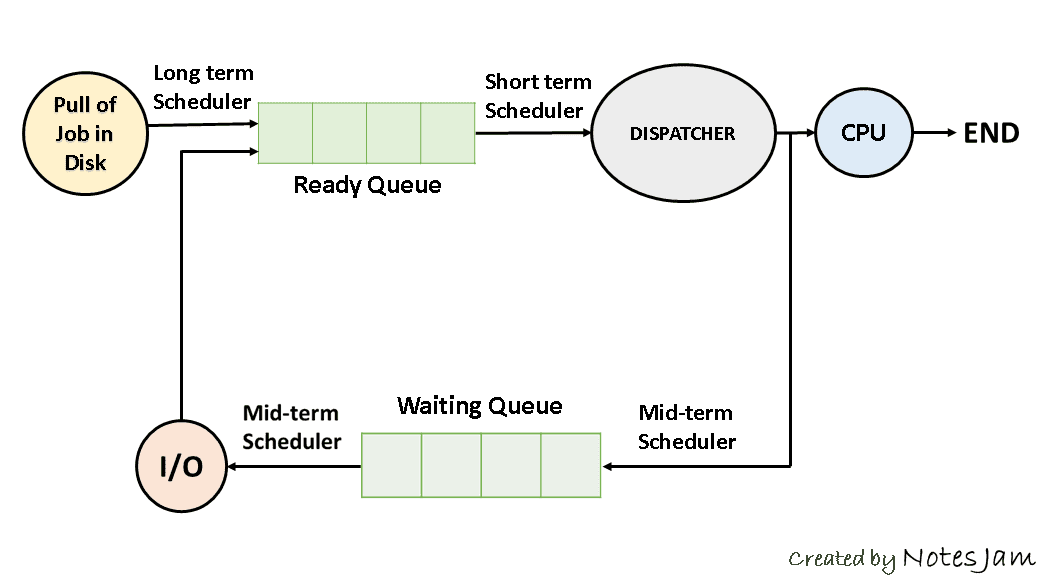
프로그램 시작전 / Job 스케줄러 / 장기)
메모리에 프로세스 올라가서 ready되기 직전에 올라와도 될지 안될지를 결정.
메모리에 몇 개 올려놓을건지를 기준으로 판단한다. degree of Muliprocess와 관련있다.
시작후 / Swaper / 중기)
메모리에 프로세스가 너무 많이 올라가있으면 몇 개를 쫓아냄.
시작후/ CPU스케줄러 / 단기)
굉장히 빨라야하고, 다음에 어떤 프로세스를 running할지 결정.
+중기 스케줄러가 확실히 성능을 개선시켜준다. 메모리를 뺏는거니까!
+Suspend상태는 사용자가 프로그램을 직접 중지시킨 경우고, 이땐 메모리에서 나와 디스크로 swap out된다.
| 동기식 입출력 | 비동기식 입출력 |
|
프로세스가 IO에 요청을 하고 완료될 때까지 자신의 일 못하는 것 scanf |
프로세스가 IO에 요청해두면 자신의 일 할 수 있는 것 timeout |
+프로세스를 너무 적게 올려놔도 안좋은 이유? 한 프로세스 IO로 블락된 동안 cpu놀고 있게 되니까.
스레드: 코드를 나눠서 처리할 수 있는 부분은 병렬적으로 따로 처리하는 것
Why?장점이 뭐길래?
->웹화면 객체 띄워지는걸 다 받아서 출력하는거보다 따로 처리해서 오는대로 보여주면 응답성 향상!
->0*10이 cpu하나면 하나하나 해야하지만 각각 나눠서 계산하고 나중에 합하는 방식도 가능
->일부 변수를 공유하기 때문에 프로세스 여러개 있는 것보다 단일 프로세스에 다중스레드 방식이 메모리 절약 됨.
어떻게 메모리를 절약하냐?
프로세스 하나->PCB 하나->프로세스상태값, 프로세스id, 메모리제한, pc, 레지스터 위치정보.
ㄴPCB는 운영체제(커널)는 프로세스들을 관리하기 위해 자신만의 메모리를 가진 것이다.
'PC와 레지스터만' 스레드들이 각각 나눠저장하고 (코드를 쪼개서 따로 풀거니까 그 코드 위치도 따로 알고 있어야 됨)
나머지는 공유한다~~아래 그림을 참고하자
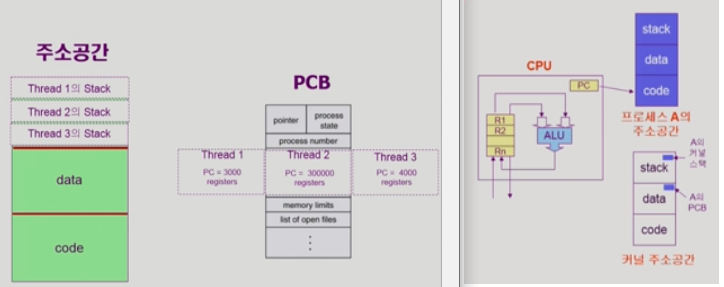
왼쪽과 오른쪽 그림을 잘 보자. 프로세스마다 주소공간을 가지고 있다.(그걸 읽으면서 동작하니까)
각 프로세스는 커널스택과 PCB 또한 나누어가진다.(정확히는 운영체제가 관리하기 위해서 프로세스별로 있는거임)
왜냐하면, 다중스레드 처리를 위해서 프로세스 PCB의 PC,레지스터를 스레드별로 구분해서 가져야 하기 때문이다.
실행할 코드를 push pop할 공간을 위해 프로세스 주소공간의 스택영역도 스레드별로 구분되어 있다.
결국 프로세스와 스레드가 공유하는 것은 data영역과 code영역이라는 것이다.(커널주소공간은 os를 위한 것이니 프로세스 관점으로 보자면)
공부한걸 바탕으로 아래 그림을 이해해보자.
공룡책 문제 빨리 풀어보자~~
| 멀티프로세스 | 멀티스레드 |
| 프로세스를 여러개 작동하는 것 | 한 프로세스를 이루는 스레드를 여러개 작동하는 것 |
| cpu를 넘겨줄 때 문맥교환 일어남(비쌈) | 문맥교환이 일어나지 않고 메모리 절약도 된다 |
| ipc를 제외하곤 메모리 공유를 하지 않는다(전면마비 안옴) | 힙을 공유하기 때문에 전면마비가 올 수 있다 |
'Basic > OS' 카테고리의 다른 글
| 가상메모리(Virtual Memory),페이지 교체 알고리즘 (2) | 2019.10.31 |
|---|---|
| 메모리 관리, 페이징, 세그멘테이션 (0) | 2019.10.26 |
| 데드락(Deadlock, 교착상태) (0) | 2019.10.18 |
| 프로세스 동기화 (0) | 2019.10.11 |
| 프로그램 생성과 종료,cpu 스케줄링 (0) | 2019.10.04 |